تنبؤ تعلم الآلة بسلوك رنين الحركة المتوسطة – الحالة المستوية
الملخص
استُخدم تعلم الآلة في الآونة الأخيرة لدراسة ديناميكيات الأنظمة الهاملتونية القابلة للتكامل ومسألة الأجسام 3 الفوضوية. في هذا العمل، نتناول حالة وسيطة للحركة المنتظمة في نظام غير قابل للتكامل: سلوك الأجسام في رنين الحركة المتوسطة 2:3 مع نبتون. نبيّن أنه، بالاستناد إلى بيانات ابتدائية مأخوذة من تكامل عددي قصير مدته 6250 سنة، تستطيع أفضل شبكة عصبونية اصطناعية (ANN) مدرّبة أن تتنبأ بمدارات الرنانات 2:3 خلال التطور اللاحق الممتد 18750 سنة، بما يغطي دورة تأرجح كاملة على امتداد الفترة الزمنية المجمعة. وبمقارنة تنبؤ شبكتنا ANN بزاوية الرنين مع نتائج التكاملات العددية، نجد أن الأولى تستطيع التنبؤ بزاوية الرنين بدقة قد تصل إلى بضع درجات فقط، مع ما تمتاز به من توفير كبير في زمن الحوسبة. وعلى نحو أدق، تستطيع الشبكة ANN المدرّبة قياس سعات الرنين للرنانات 2:3 بفعالية، ومن ثم توفر نهجًا سريعًا قادرًا على تحديد المرشحين الرنينيين. وقد يكون ذلك مفيدًا في تصنيف جمهرة هائلة من أجسام حزام كايبر KBOs المنتظر اكتشافها في المسوحات المستقبلية.
keywords:
الميكانيكا السماوية – حزام كايبر: عام – الكواكب والأقمار: التطور والاستقرار الديناميكيان – الطرائق: عددية1 مقدمة
صُممت الشبكات العصبونية للتعرّف إلى الأنماط عبر تقريب الدالة الملائمة بين المتغيرات المشتركة (أي المدخلات) والمتغيرات التابعة (أي المخرجات) بوصفها صندوقًا أسود (McCulloch & Pitts, 1943; Rosenblatt, 1958). وقد استُلهمت الشبكات العصبونية الاصطناعية (ANNs) من الدماغ البشري، لكنها أصبحت تدريجيًا مختلفة عن نموذجها الحيوي الأولي. وهذا يشبه إلى حد بعيد تصميم الطائرات المستلهم من الطيور، مع أن مبدأ الطيران لم يؤخذ من الطيور. وقد طُبقت هذه الاستراتيجية بكفاءة على طيف واسع من مسائل التعرف إلى الأنماط في العلم والصناعة. عادةً ما تتعامل ANNs مع مهام تعلم آلي كبيرة ومعقدة، مثل تصنيف الصور عالية الجودة (مثل ImageNet)، والتعرّف إلى الصوت أو الكلام (مثل Siri)، والتوصية بالسلع للزبائن (مثل YouTube و Amazon). وفي الواقع، فإن ANNs نماذج مدفوعة بالبيانات وقد تمتلك قدرة قوية على الاستكشاف الذاتي للعلاقة بين المدخلات والمخرجات في الأنظمة الفيزيائية المجهولة.
في تعلم الآلة، تمثل الشبكات العصبونية الالتفافية (CNNs) صنفًا من ANNs، وتُطبّق على نحو شائع لتحليل الصور المرئية (Valueva et al., 2020). وبسبب الزيادة الكبيرة في القدرة الحاسوبية خلال السنوات القليلة الماضية، أُديرت CNNs بحيث تحقق أداءً يفوق الأداء البشري في كثير من المهام البصرية المعقدة، كما في خدمات البحث عن الصور مثلًا (Bell, Bala, 2015; Qayyum et al., 2017)، والسيارات ذاتية القيادة (Sanil et al., 2020; Stroescu et al., 2019)، والتصنيف الآلي للفيديو (Karpathy et al., 2014; Ng et al., 2015). والأكثر إثارة للاهتمام أن CNNs ثبت نجاحها أيضًا في التنبؤ بالسلاسل الزمنية (Sezer et al., 2020). وللاطلاع على وصف مفصل لـ CNNs، يُحال القارئ إلى الكتابين اللذين ألّفهما Géron (2017) و Brownlee (2018).
في مجال الفلك والفيزياء الفلكية، طُبقت طريقة تعلم الآلة على نطاق واسع بالفعل في اكتشاف الكواكب الخارجية (Mislis, Pyrzas & Alsubai, 2018; Schanche et al., 2019; Armstrong, Gamper & Damoulas, 2021)، وكشف انفجارات أشعة غاما (Ukwatta, Woźniak & Gehrels, 2016; Abraham et al., 2021)، وتصنيف المجرات (Sun et al., 2019; Zhang et al., 2019; Baqui et al., 2021; Vavilova et al., 2021)، ودراسة المادة المظلمة (Agarwal, Davé & Bassett, 2018; Lucie-Smith, Peiris & Pontzen, 2019; Petulante et al., 2021). أما بالنسبة إلى مسألة الأجسام n الكلاسيكية في الميكانيكا السماوية، فلم تبدأ الدراسة ذات الصلة إلا حديثًا جدًا. فقد قصد Breen et al. (2020) حل مسألة الأجسام 3 العامة بواسطة تدريب شبكة ANN عميقة (أي ذات أكثر من 1 طبقة مخفية). وفي الحالة المستوية، يبيّنون أن الشبكة ANN العميقة تستطيع تقديم حلول بدقة مماثلة لتلك الناتجة من التكامل العددي، لكن بتكلفة حاسوبية أقل بكثير. غير أننا نلاحظ أن شبكتهم ANN الأفضل أداءً دُربت لمسارات ذات زمن تطور يبلغ وحدات زمنية. وباعتماد وحدات مماثلة عديمة الأبعاد في نظام شمسي مبسط يتألف من الشمس وكوكب وكويكب، فإن هذا الفاصل الزمني لا يتجاوز رتبة مئات السنين، أما على المقاييس الزمنية الأطول أو فإن الخسارة على مجموعة التحقق تصبح أكبر بكثير.
إن الاعتماد القوي لدقة حل الشبكة ANN على زمن تطور نظام الأجسام 3 أمر مباشر تمامًا، لأن هذا النظام الديناميكي فوضوي (Poincaré, 1892). فالأنظمة الفوضوية شديدة الحساسية للشروط الابتدائية، إذ قد تؤدي تغييرات طفيفة في المدخلات إلى مخرجات طويلة الأمد مختلفة اختلافًا كبيرًا. لذلك فإن التنبؤ بتطور المسار لمدة أطول من زمن ليابونوف، أي مقلوب الأس المميز لليابونوف، هو أمر بالغ الصعوبة جوهريًا. ومن ناحية أخرى، وبما أن دقة التنبؤ حساسة أيضًا لأنماط مجموعتي التدريب والتحقق (Breen et al., 2020)، فإن بناء ANNs للمسألة الفوضوية يكون مهمة معقدة. درس Greydanus, Dzamba & Yosinski (2019) أنظمة هاملتونية قابلة للتكامل تكون الحركة فيها منتظمة في كل مكان، مثل نابض-كتلة مثالي وبندول مثالي. ولمثل هذه الأنظمة، صمموا ما يسمى بالشبكات العصبونية الهاملتونية لتعلم قوانين الفيزياء مباشرة من البيانات، وكذلك حفظ الكميات الشبيهة بالطاقة على مقياس زمني طويل.
علاوة على ذلك، توجد أدبيات حول تعلم الآلة في الديناميكيات المدارية. فقد بيّن Tamayo et al. (2016) أن توصيف حد الاستقرار المعقد ومتعدد الأبعاد للأنظمة المكتظة بإحكام ملائم لخوارزمية تعلم آلي من نوع XGBoost. وجمع Tamayo et al. (2020) الفهم التحليلي لديناميكيات الرنين في أنظمة كوكبين مع تقنيات تعلم الآلة لتدريب نموذج قادر على تصنيف الاستقرار تصنيفًا متينًا في أنظمة متعددة الكواكب ومضغوطة على مقاييس زمنية طويلة تبلغ مدار. وقدّم Cranmer et al. (2021) نموذج شبكة عصبونية بايزية للتنبؤ بموعد فقدان نظام كوكبي مضغوط يحوي ثلاثة كواكب أو أكثر لاستقراره. ودُرب نموذجهم مباشرة من سلاسل زمنية قصيرة للعناصر المدارية الخام، وكذلك من أعمال متعلقة بالاستقرار المداري (Lam & Kipping, 2018; Bhamare et al., 2021). ونود أن نشير إلى أن جميع تلك الأعمال المشابهة، إلى جانب Breen et al. (2020)، لا تدرس إلا الحالة المستوية. وهذا الاختيار معقول تمامًا لأنه يتطلب قدرة حاسوبية أدنى من الحالة الفضائية.
1.1 حزام كايبر ودراسة تعلم الآلة
في النظام الشمسي الخارجي وراء مدار نبتون، يوجد عدد كبير من الأجرام السماوية الجليدية المعروفة بأجسام حزام كايبر (KBOs). ومن السمات اللافتة أن الجمهرة الواقعة في رنين الحركة المتوسطة (MMR) مع نبتون تشكل نسبة عالية من KBOs المرصودة (Gladman et al., 2008; Khain et al., 2020). وحتى الآن، وُجد أن نحو 400 جسمًا تتجمع في MMR 2:3 عند نحو 39.4 وحدة فلكية، ولها شذوذات مركزية تصل إلى 0.3. وتمثل خصائصها الديناميكية أدلة مهمة على التاريخ المبكر لنظامنا الكوكبي. فعلى سبيل المثال، تقدم هذه الأجسام دليلًا راسخًا على أن الكواكب المشتروية شهدت هجرة مدارية كبيرة (Malhotra, 1993, 1995). وأثناء هجرة نبتون إلى الخارج، التقط رنينه 2:3 كثيرًا من الكواكب المصغرة بما فيها بلوتو، وأثار أيضًا شذوذاتها المركزية. ومنذ عقد 1990، حظي أصل KBOs الرنانة وتطورها باهتمام كبير (Hahn & Malhotra, 2005; Li et al., 2011; Nesvorný & Vokrouhlický, 2016; Volk et al., 2016; Pike & Lawler, 2017; Yu et al., 2018; Lawler et al., 2019). ونتيجة للمسوحات الجارية، يُتوقع اكتشاف عدد أكبر بكثير من KBOs في المستقبل القريب؛ فمثلًا سيسهم تلسكوب المسح الشامل الكبير (LSST) إسهامًا مهمًا باكتشاف نحو 30,000 من KBOs (Ivezić et al., 2019). ومن ثم فإن البنية المنقحة للجمهرة الرنانة ستساعد على زيادة تحسين سيناريو هجرة الكواكب.
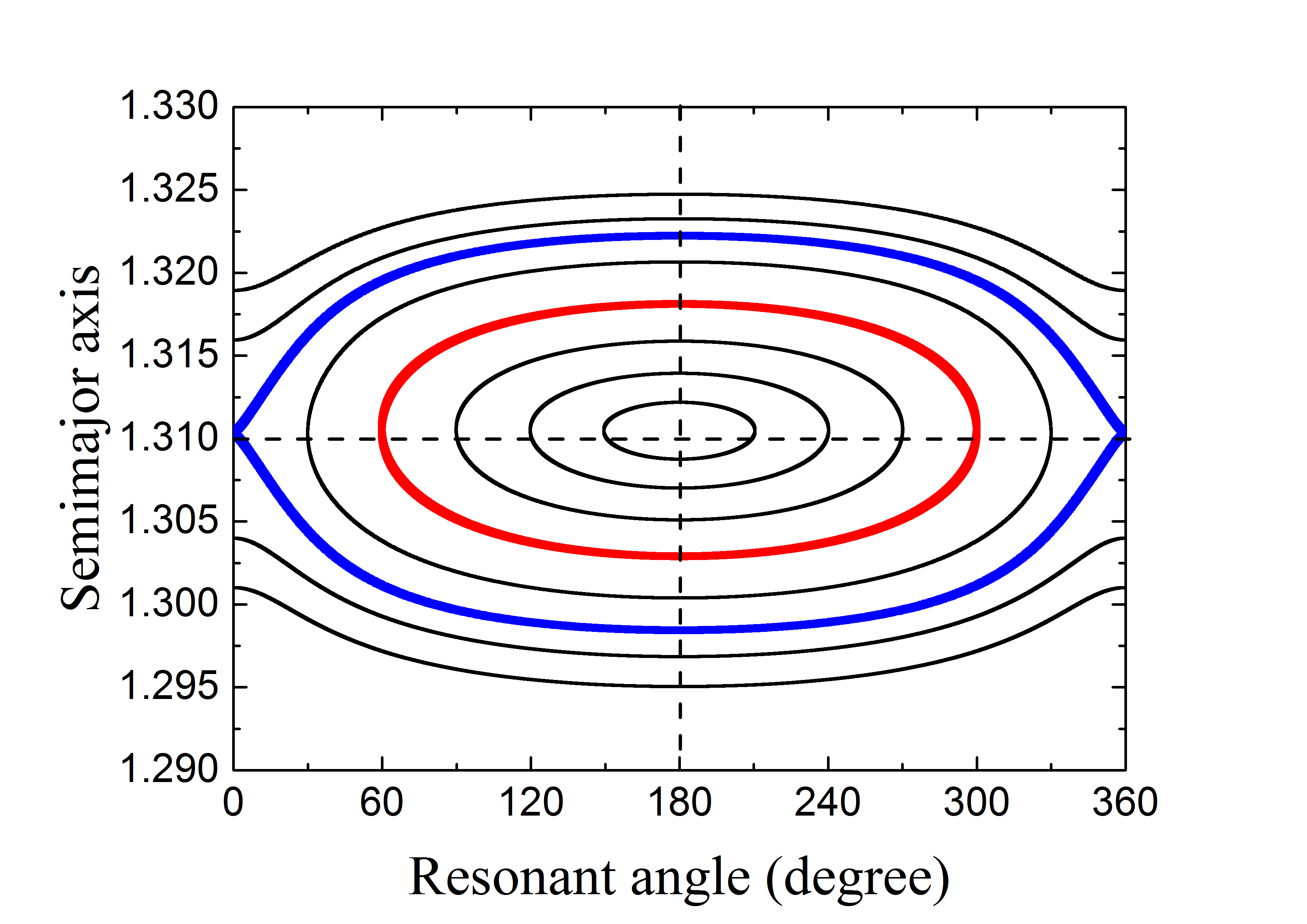
في إطار مسألة الأجسام 3 المقيدة الدائرية المستوية (PCR3BP)، أي الشمس+نبتون+جسيم، نهدف إلى استكشاف أداء الشبكة ANN في تعلم التطور الديناميكي للجسيمات في الرنين 2:3 مع نبتون. أما اعتماد النموذج المستوي، فالقيد الحاسوبي أحد الاعتبارات كما لاحظنا في الأعمال المذكورة آنفًا؛ إضافة إلى ذلك، فإن هذا الرنين 2:3 هو في الواقع رنين من نوع الشذوذ المركزي (Li et al., 2020)، وتتحدد سماته الديناميكية تقريبًا بشذوذ الجسيم المركزي لا بميله. وعلى الرغم من أن PCR3BP هي أبسط نموذج في مسألة الأجسام 3، فإنها تحتوي على حركات فوضوية ومنتظمة معًا. وعندما لا يكون شذوذ الجسيم المركزي كبيرًا جدًا، لا توجد في فضاء الطور الخاص بـ MMR 2:3 إلا طارات لامتغيرة (انظر الشكل 1)، ومن ثم تكون الحركة منتظمة دائمًا. والهدف الأول لهذا العمل هو تدريب شبكة ANN، خلال فاصل زمني طويل وثابت، للتنبؤ بدقة بسلوك الحركة الرنانة المنتظمة.
أما هدفنا الثاني فهو تقديم نهج سريع لتحديد KBOs الرنانة. وبما أن الشبكة ANN المدرّبة قد تتنبأ بتطور الجسيمات أسرع بكثير من التكاملات العددية، يمكننا قياس سعات الرنين تبعًا لذلك في زمن حوسبة قصير جدًا. ولم يبدأ تصنيف التعلم الآلي للجماعات الرنانة في النظام الشمسي إلا في العام الماضي. فقد استخدم Smullen & Volk (2020) مصنف شجرة قرار مدرّبًا على سمات مدارية متنوعة لفرز KBOs إلى أربع فئات ديناميكية: الأجسام الكلاسيكية والرنانة والمنفصلة والمبعثرة. إضافة إلى ذلك، وبخصوص كويكبات الحزام الرئيسي في MMR 1:2 مع المريخ، طبّق Carruba et al. (2021) شبكة ANN للتعرّف إلى صور زوايا الرنين المتغيرة زمنيًا، ثم لتصنيف المدارات المتأرجحة والمتبدلة والدائرية. وفي العملين المذكورين أعلاه، يلزم تكامل عددي مدته سنة لتوليد المسارات المراد تحديدها. ونهدف إلى تقليل الفاصل الزمني للتكامل العددي أكثر، وترك الشبكة ANN تتنبأ بالمسارات المدروسة على مقياس زمني أطول ما يمكن.
تنظم بقية هذه الورقة على النحو الآتي: في القسم 2، نعرض بإيجاز نموذج PCR3BP، وكيفية توليد العينات في MMR 2:3 لنبتون من أجل مجموعتي التدريب والتحقق. وفي القسم 3، نصف كيف نصمم ANNs الخاصة بنا وندربها، ونبيّن اعتماد النتائج على بنية مجموعة التدريب. وفي القسم 4، نطبق ANNs المدرّبة على جسيمات في الرنين المستقر 2:3، للتنبؤ بالتطور المداري وتحديد السلوك الرنيني. وأخيرًا تُعرض الاستنتاجات والمناقشة في القسم 5 والقسم 6، على التوالي.
2 توليد بيانات التعلم للرنين 2:3
2.1 نموذج PCR3BP
نعتمد PCR3BP لنمذجة الجسيمات في MMR 2:3 مع نبتون ولتوليد مجموعات البيانات لتعلم الآلة. وفي إطار هذا النموذج الديناميكي، نشير إلى الشمس ذات الكتلة بوصفها الجسم الأولي، وإلى كوكب نبتون ذي الكتلة بوصفه الجسم الثانوي، وإلى جسيم عديم الكتلة بوصفه الجسم الثالث. يؤثر الجسمان الأولي والثانوي بقوى الجاذبية في الجسيم، لكنهما لا يتأثران به؛ وتقع حركات الأجسام الثلاثة كلها في المستوى نفسه.
بما أن الشمس ونبتون يتحركان على مدارين دائريين حول مركز كتلتهما المشترك ، فلهما مسافة متبادلة ثابتة وسرعة زاوية واحدة . ومن المعتاد اختيار المعاملات اللابعدية بالطريقة الآتية: الكتلة الكلية للنظام ، والفصل ، والسرعة الزاوية . وبالنظر إلى هذه الوحدات، يكون ثابت الجاذبية مساويًا أيضًا لـ 1. استخدمنا نظام الإحداثيات السينودية ، الذي يقع أصله عند ويدور بمعدل منتظم في الاتجاه الموجب لحركة نبتون المدارية. ويختار محور بحيث تقع الشمس ونبتون دائمًا عليه بإحداثيين و ، على التوالي، حيث نسبة الكتلة .
في النظام السينودي ، تكون معادلات حركة الجسيم عديم الكتلة
| (1) |
حيث يُعطى ”الجهد الزائف” بالعلاقة
| (2) |
وتكون و مسافتي الجسيم إلى الشمس ونبتون، على التوالي:
| (3) |
للنظام التفاضلي المعطى في المعادلة (1) ثابت حركة يُعرف بتكامل ياكوبي:
| (4) |
وسوف يُستخدم هذا الثابت لوضع قيود على حركة الجسيمات سواء في التكامل العددي أو في تنبؤ تعلم الآلة.
2.2 العينات الرنانة 2:3
نعد الجسيم مقيدًا في MMR 2:3 لنبتون إذا كان وسيط الرنين الحرج
| (5) |
يتأرجح حول ، حيث إن و هما خط الطول المتوسط وخط طول الحضيض للجسيم، و هو خط الطول المتوسط لنبتون.
من أجل توليد جمهرة رنانة في MMR 2:3 لنبتون، تُعطى الشروط الابتدائية للجسيمات بدلالة العناصر المدارية ، حيث نصف المحور الرئيسي و الشذوذ المركزي. أخذنا عينات من جسيمات تبدأ عند موضع الرنين الاسمي 2:3، المعرّف بأنه (Gallardo, 2006). لاحظ أنه في PCR3BP تكون زاوية الرنين لامتغيرة إزاء التغيرات في (المشار إليها بـ ) إذا أدرنا نظام الإحداثيات ببساطة حول الأصل بالزاوية ؛ لذلك تؤخذ قيمة اعتباطية مقدارها . وعندئذ يمكن تحديد القيمة الابتدائية لـ من معطاة بواسطة المعادلة (5).
كما هو موضح في الشكل 1، عند صغير نسبيًا، يكون فضاء الطور لـ MMR 2:3 منتظمًا في كل مكان، ولا يوجد إلا مركز تأرجح متناظر له و . وبما أن اختير مساويًا لـ ، فإن زاوية الرنين الابتدائية تقيس سعة الرنين ، أي الانحراف الأعظمي لـ عن مركز الرنين عند . ومن المهم ذكر أن جزءًا كبيرًا من KBOs الرنانة 2:3 المرصودة يوجد على مدارات أكبر شذوذًا (مثل بلوتو ذي )، وهي مدارات قد تظهر فيها الحركة الفوضوية عند كبيرة (Malhotra, 1996). ومع ذلك، ووفقًا لعملنا السابق (Li, Zhou & Sun, 2014)، يمكن أن تبقى KBOs الرنانة 2:3 ذات حتى 0.3 مستقرة على مدى عمر النظام الشمسي إذا كانت سعات رنينها . لذلك، وبالنسبة إلى العينات الرنانة المستخدمة لتوليد بيانات تعلم الآلة، ستُقيد زوايا الرنين الابتدائية في المنطقة ، المحصورة بالكفاف الأحمر لـ في الشكل 1. وفي بقية هذه الورقة، ننظر أولًا في حالة للرنانات 2:3. وإذا ثبتت فعالية الشبكة ANN في التنبؤ بسلوكها الرنيني، فسنعِّمم نتائجنا على الحالات الأعلى شذوذًا ذات و .
بالنسبة إلى جسيم مأخوذ عينة، عندما تُعطى مجموعة ابتدائية ، يمكننا حساب المواضع الابتدائية المقابلة والسرعات . ثم ننشر معادلات الحركة عدديًا، أي المعادلات (1)، في الإطار السينودي على مقياس زمني قدره سنة. ويُجرى التكامل العددي باستخدام مكامل Runge-Kutta من الرتبة 8 وبخطوة زمنية سنة، وهو قادر على إبقاء درجة الخطأ المرغوبة دون . والمقياس الزمني المعتمد يكافئ 100 مدارًا عند موضع بلوتو، وهو طويل بما يكفي لرؤية دورة تأرجح كاملة للجسيمات الرنانة 2:3 النموذجية. لذلك يمكننا تحديد سعة رنين الجسيم ، وكذلك السلوك الرنيني أو غير الرنيني. ويختار الفاصل الزمني بين الخرجين المتتاليين في التكامل مساويًا لـ /99، بحيث يتألف المسار من مجموعة بيانات ذات 100 نقطة منفصلة () عند الزمن الموافق (). وبناءً على ذلك، يمكننا استنتاج العناصر المدارية ()، وهي في الإطار العطالي المركزي الشمسي.
من خلال العملية السابقة، نولّد مجموعة تدريب تحتوي على 10000 مسار، تكون زوايا الرنين الابتدائية فيها مختارة عشوائيًا بين و ، أي . ولكل مسار 100 نقطة مدارية موصوفة بأربع متغيرات مشتركة ذات الفاصل الزمني نفسه. وسوف يُشار إلى هذه التجربة الأولى باسم Train \@slowromancapi@ (انظر الجدول 1). أما بالنسبة إلى مجموعة التحقق، فنستخدم 1000 مسارًا تبدأ داخل منطقة نفسها، مع توزيع منتظم بدقة . وبهذه الطريقة، يمكن أن تكون المسارات في مجموعة التحقق قريبة من تلك الموجودة في مجموعة التدريب، لكنها لا تتداخل معها.
3 منهج التعلم
3.1 تهيئة شبكة ANN
بهدف التنبؤ بالحركات الرنانة للجسيمات في PCR3BP، نبني الشبكة ANN لتتعلم من مجموعة التدريب (أي Train \@slowromancapi@)، ثم نقيم دقة التنبؤ باستخدام مجموعة التحقق. وقد وُصفت بنيتا هاتين المجموعتين أعلاه مباشرة. ولاختبار ما إذا كان بوسع الشبكة ANN تقديم تنبؤات دقيقة للسلوكيات الرنانة، نركز أولًا على الجسيمات ذات الصغيرة. وكما يظهر في الشكل 1، فإن مسارات هذه الجسيمات مقيدة بالطارات اللامتغيرة في منطقة التأرجح، ولذلك تُعد حركاتها منتظمة.
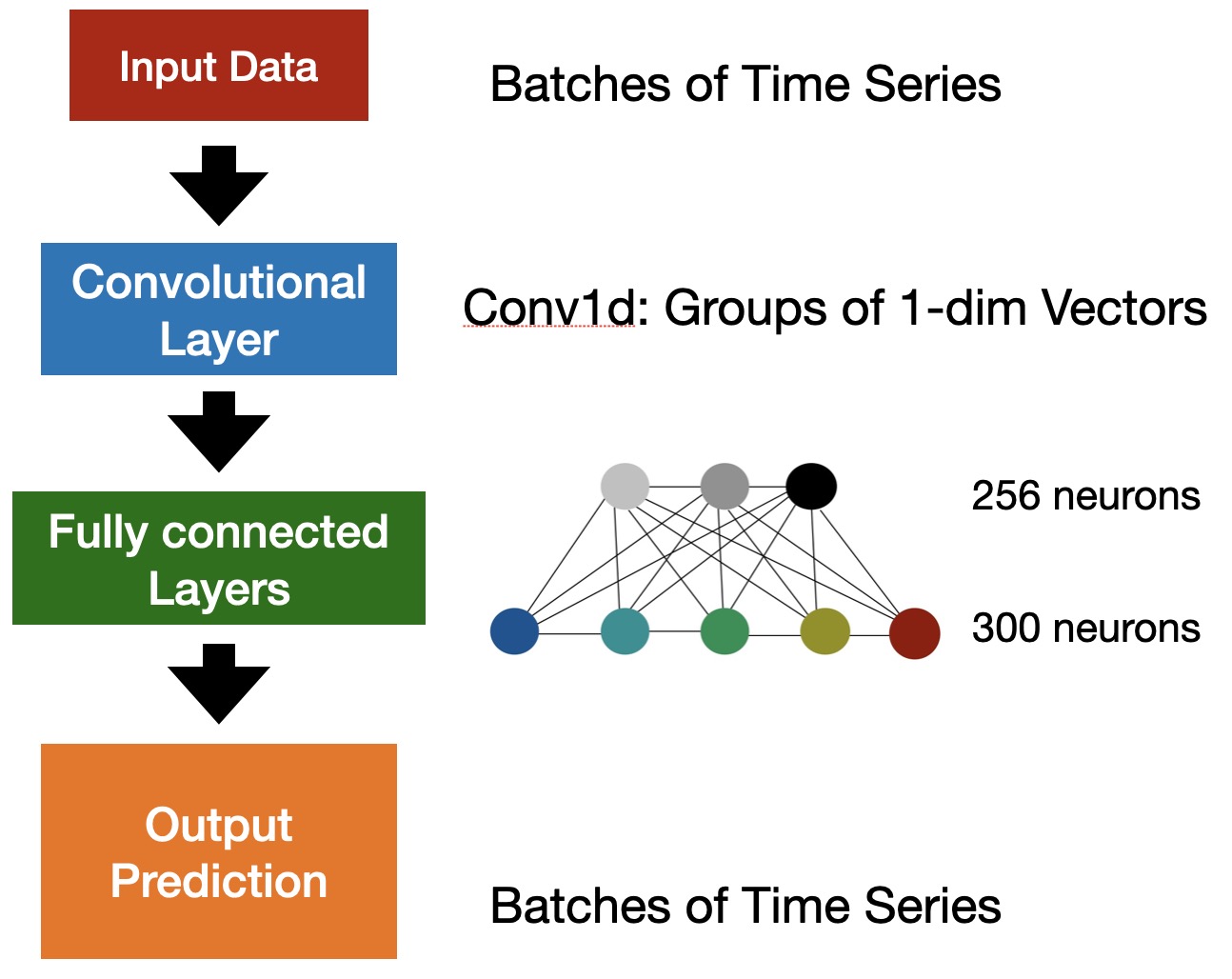
أُجريت كل التجارب الآتية في Pytorch. أنشأنا شبكة ANN ذات تغذية أمامية تتألف من 5 طبقات: 1 طبقة إدخال، و 1 طبقة التفاف، و 2 طبقات تامة الاتصال، و 1 طبقة إخراج (الشكل 2). وتسمى طبقة الالتفاف والطبقات تامة الاتصال عادةً الطبقات المخفية. وطبقة الالتفاف هي أهم لبنة في CNN، كما ذكرنا في المقدمة. وضمن إطار Pytorch، طبقنا طبقة التفاف 1-بعدية (Conv1d)، وضبطنا حجم قنوات الإدخال والإخراج على 4 و 10، على التوالي، واتخذنا حجم نواة الالتفاف مساويًا لـ 1. وكمية قنوات الإدخال مساوية لبعد المجموعة متعددة المتغيرات ، أما عدد قنوات الإخراج فهو عدد الالتفافات في الطبقة. وللطبقتين التاليتين تامتي الاتصال 256 و 300 عصبونًا، على التوالي. وفي جميع المهام، دربنا النماذج بمعدل تعلم واعتمدنا محسن Adam (Kingma & Ba, 2015).
تُسنَد الأوزان ابتدائيًا من توزيع غاوسي على جميع الطبقات المخفية للشبكة. وبالنظر إلى القدرة الحاسوبية، ضبطنا حجم الدفعة على 100، أي إننا فصلنا بيانات التدريب إلى 100 دفعات. ويمكن أن تساعد هذه الحيلة أيضًا في تقليل الخسارة بكفاءة أثناء عملية التعلم. ونختار دالة تنشيط الوحدة الخطية المصححة المعتادة (ReLU) في جميع الطبقات المخفية (Nair & Hinton, 2010). لنفترض أن لدينا بيانات إدخال ، وأن أوزان الاتصال بين طبقتي الإدخال والمخفية هي . عندئذ يكون المتغير الوسيط ، وتكون لدينا دالة التنشيط مؤثرة في . وتُدخل دالة التنشيط الآثار غير الخطية للمسألة المراد حلها، ولذلك فهي نقطة أساسية تساعد ANN على التقارب بسهولة أكبر. وجربنا أيضًا دوال تنشيط مختلفة، مثل دالة الوحدة الخطية المصححة المتسربة (Maas, Hannun & Ng, 2013) والدالة المصححة الأسية (Clevert, Unterthiner & Hochreiter, 2016). غير أنه لم يتحقق أي تحسن ظاهر.
3.2 عملية التدريب
بعد ذلك أُجري تدريب الشبكة، عبر التعلم من بيانات التدريب وضبط الأوزان لتقليل الخسارة. وتحتوي كل حقبة تدريبية على مرور أمامي-عكسي كامل عبر بيانات التدريب. وتُعرف استراتيجية التدريب هذه جيدًا باسم الانتشار العكسي (Rumelhart, Hinton & Williams, 1986).
يُنفذ المرور الأمامي أولًا. وبالنسبة إلى النقاط الزمنية 100 لكل مسار، نُدخل أول نقطة () () إلى طبقة الإدخال. وتحسب الخوارزمية النتيجة الوسيطة لكل عصبون في الطبقات المخفية. وأخيرًا تُرجع طبقة الإخراج النقاط المتنبأ بها اللاحقة وعددها ، (). ويمكن قياس دقة ANN بواسطة الخسارة . وبالمقارنة مع الوسوم عند الزمن المقابل ()، تُعرّف الخسارة بأنها
| (6) | |||||
ومن الآن فصاعدًا، سنرمز إلى الخسارتين على مجموعتي التدريب والتحقق بـ و ، على التوالي.
ثم يبدأ المرور العكسي. فبالنظر إلى خسارة كل عصبون في طبقة الإخراج، تحسب خوارزميتنا إلى الخلف مساهمة كل عصبون في الطبقة المخفية الأخيرة، عبر الوصلات بين هاتين الطبقتين باستخدام قاعدة السلسلة. ثم، وبخصوص المحصلة، تواصل الخوارزمية تقييم المساهمة لكل عصبون في الطبقة المخفية السابقة. وتتوقف هذه العملية عندما يصل حساب هذه المساهمة إلى طبقة الإدخال. وعند هذه المرحلة نحصل على تدرج الخسارة إلى الخلف عبر جميع الأوزان على روابط الاتصال. وفي مرحلة المرور العكسي، يُعتمد تحسين Adam لتقليل الخسارة عبر تعديل أوزان الاتصال.
| Training set | Cumulative number | |||
|---|---|---|---|---|
| Train \@slowromancapi@ | [, ] | (i.e. constant) | ||
| Train \@slowromancapii@ | [, ] | |||
| Train \@slowromancapiii@ | [, ] |
أثناء عملية التدريب، يحتاج المرء إلى تنقيح جميع المعلمات الفائقة (مثل اختيار دوال التنشيط وعدد الطبقات أو العصبونات المخفية)، لضمان أن خسارة التدريب يمكن أن تنخفض إجمالًا مع زيادة عدد الحقب، وأن تصل دقة التنبؤ على مجموعة التدريب إلى مستوى معقول. ونتيجة لذلك اختيرت دالة تنشيط ReLU، وحُددت بنية ANN الموضحة في الشكل 2. لنفترض أن التدريب عند الحقبة ؛ إذا كانت الخسارة المحصلة أصغر من القيم السابقة ، فستُحفظ جميع أوزان الاتصال في ANN.
توجد معلمة مهمة ينبغي تحديدها. وتتدرج قيمة مع سرعة الحصول على مسار. كانت فكرتنا الأولى تجربة ، أي استخدام النقطة الزمنية الأولى فقط من المسار للتنبؤ بالنقاط 99 اللاحقة. لكن في هذه الحالة نجد أن الخسارة توقفت عن الانخفاض وهي ما تزال ذات قيمة كبيرة نسبيًا. ومن السهل فهم ذلك لأن معلومات الإدخال غير كافية لتوصيف تطور الحركة الرنانة. لذلك يتعين علينا اختيار قيمة أكبر لـ . وبعد بعض التجارب، قررنا اعتماد ، وهو ما يقارب طول 1/4 من فترة التأرجح، وينتج تنبؤًا أدق بكثير للنقاط الزمنية اللاحقة وعددها 75. وفي هذه الحالة، نستطيع توفير زمن حوسبة بمستوى ، أي 75%. وفي الواقع، إذا استخدمنا قيمة أكبر حتى لـ ، مثل ، فإن قد تنخفض بالتأكيد أكثر، لكن لن يبقى إلا نقطة زمنية واحدة للتنبؤ بها. وفي هذه الحالة، لا تستطيع طريقة تعلم الآلة تسريع الحساب المداري بفعالية، فتفشل في تحقيق الهدف الرئيس لعملنا.
نراقب أيضًا تغير خسارة التحقق طوال حسابنا. وفي الواقع، تحسب ANN تلقائيًا، في كل حقبة، كلًا من و . وتُظهر النتيجة اتجاهًا عامًا لانخفاض مع زيادة الحقبة أثناء عملية التدريب. وهنا نحتاج إلى توضيح أن لم تُستخدم قط لاتخاذ أي قرار بشأن بنية ANN أو اختيارات جميع أوزان الاتصال، بل تمثل فقط قدرة الشبكة ANN المدرّبة على التعميم. وسيُعرض مخطط الخسارة في القسم الفرعي التالي.
3.3 التحقق من شبكة ANN
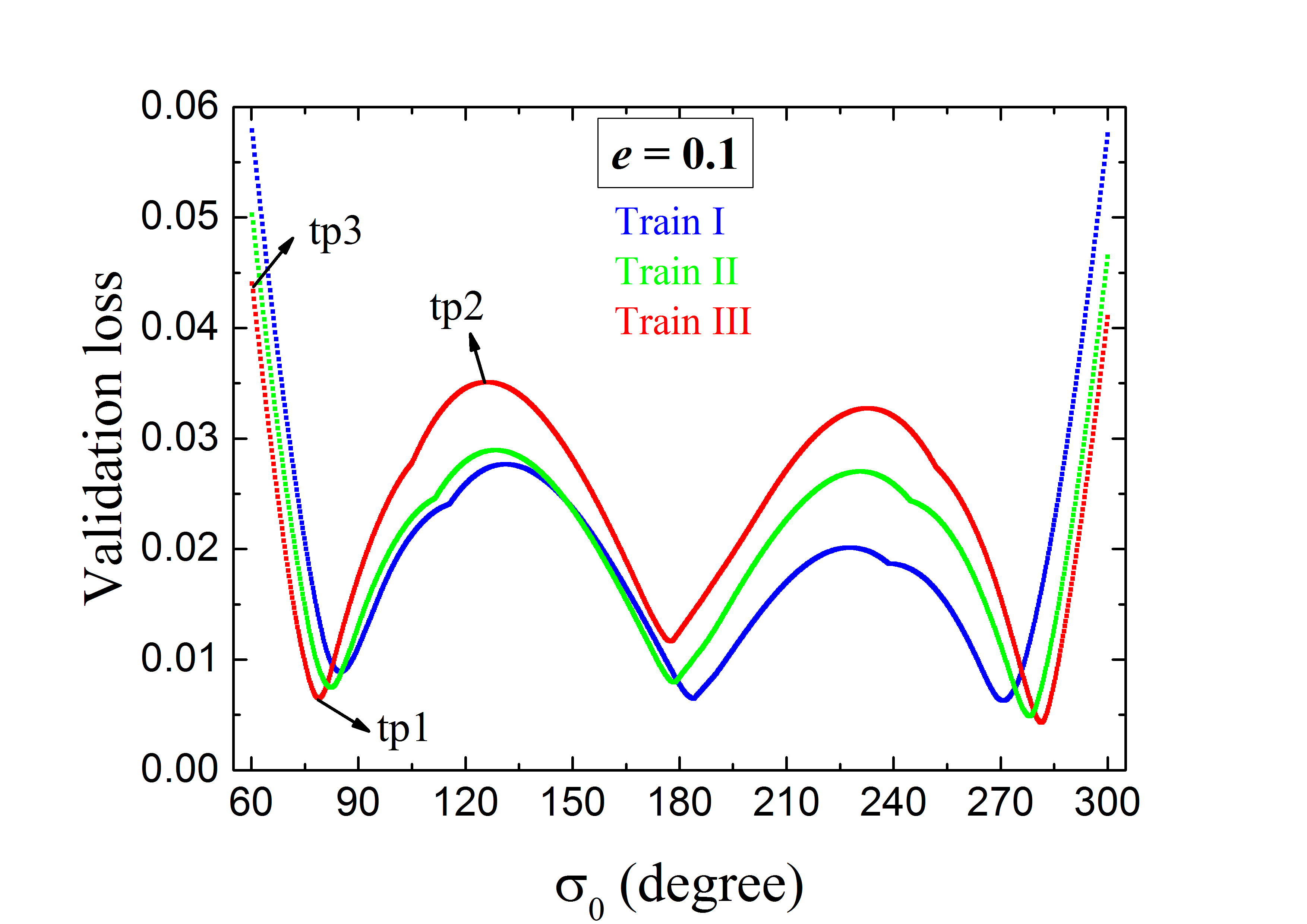
في جميع مهامنا، بعد 3000 حقبة، تبين أن خسائر التدريب صغيرة جدًا وتكاد تكون قد توقفت عن الانخفاض. وفي الوقت نفسه لا تبدو خسائر التحقق آخذة في الزيادة، مما يشير إلى عدم وجود مشكلة فرط ملاءمة للبيانات. لذلك نفترض أن دقة التنبؤ قد تكون مقبولة، وسُجلت جميع البيانات عند الحقبة 3000 تحديدًا. يبيّن الشكل 3، بالنسبة إلى ANN المدرّبة بالمجموعة Train \@slowromancapi@ (المنحنى الأزرق)، خسارة التحقق بوصفها دالة في زاوية الرنين الابتدائية . ونرى أن قيم صغيرة جدًا () قرب مركز الرنين عند . وعلى الرغم من وجود قمتين حول و ، فإن ارتفاعيهما ليسا إلا من رتبة . غير أن قد تزداد بوضوح للجسيمات التي تبدأ أبعد ما يمكن عن مركز الرنين، وتبلغ العظمى عند طرفي منحنى الخسارة (الأزرق). وحتى إذا واصلنا تشغيل مزيد من الحقب، لا يحدث إلا انخفاض ضئيل في العظمى حول نقطتي الحد لفاصل . ولتجاوز هذا العيب، بذلنا جهودًا أيضًا للبحث عن حل أمثل محلي أفضل لتدريب ANN، باعتماد بعض خوارزميات التحسين الأخرى مثل خوارزمية تدرج تكيفية تسمى AdaGrad (Duchi, Hazan & Singer, 2011) وطريقة الانحدار التدرجي العشوائي (SGD). غير أن أداءهما لم يكن جيدًا حتى بمستوى محسن Adam الذي اخترناه سابقًا.
ثم أدركنا أن أكبر ، الذي يظهر أبعد ما يمكن عن مركز الرنين، قد يعود إلى عدم كفاية معلومات الإدخال للجسيمات الرنانة المقابلة. ففي مجموعة التدريب Train \@slowromancapi@، تكون للعينات زوايا رنين ابتدائية موزعة بانتظام بالنسبة إلى مركز الرنين عند . وكما أشرنا سابقًا، يمكن قياس سعة الرنين ببساطة من انحراف عن . وهذا يعني أن كثافة العدد تتناسب مع ، أي إنها ثابتة. ومن ثم نتوقع أن هذه المشكلة يمكن إصلاحها بزيادة كثافة العدد عند الأكبر. وبناءً على ذلك، نبني داخل منطقة الرنين المدروسة مجموعتي تدريب أخريين تتألفان من جسيمات تزداد فيها حسب و . وسيُشار إلى هاتين المجموعتين باسم Train \@slowromancapii@ و Train \@slowromancapiii@ (انظر الجدول 1). وبالنسبة إلى Train \@slowromancapii@ و Train \@slowromancapiii@، تكون الأعداد التراكمية للجسيمات داخل طار معين موصوف بـ متناسبة على التوالي مع و . وباستثناء بيانات التدريب، تُبقى بنية ANN ومجموعة التحقق كما هما، وستُعرض النتائج في القسم التالي.
4 النتائج
4.1 حالة
لتدريب ANN باستخدام Train \@slowromancapii@ أو Train \@slowromancapiii@، يُضبط عدد الحقب أيضًا على 3000 كما في العدد المستخدم لـ Train \@slowromancapi@. ومن حين إلى آخر، فحصنا بصريًا مخطط خسارة التحقق لنرى كيفية أداء ANN. وفي نهاية سيناريوَي التدريب المختلفين كليهما، كانت قيم الإجمالية قد توقفت بالفعل عن الانخفاض. وتُرسم منحنيات الخسارة الفردية في الشكل 3.
يُعرض مخطط الخسارة الموافق لـ Train \@slowromancapii@ بالمنحنى الأخضر في الشكل 3. ونرى أن الخسائر عند الطرفين تبلغ نحو 0.05، وهي أصغر بنسبة % من حالة Train \@slowromancapi@ (المنحنى الأزرق)؛ في حين تزداد الخسائر المركزية قليلًا. وهذا الاتجاه طبيعي بسبب اختلاف توزيعات العدد في Train \@slowromancapi@ و Train \@slowromancapii@. فالأخيرة لها توزيع عددي أشد انحدارًا () من الأولى ()، وبياناتها أوفر عند الأكبر (المكافئة لزاوية الرنين الابتدائية ). وبذلك يمكننا تبرير التحسن الواضح في تدريب ANN باعتماد المجموعة Train \@slowromancapii@.
وعندما نواصل زيادة حدة التوزيع العددي لعينات التدريب إلى ، أي باستخدام مجموعة التدريب Train \@slowromancapiii@، لا يزال مخطط الخسارة (المنحنى الأحمر في الشكل 3) يتبع الاتجاه الموصوف سابقًا: انخفاض عند الطرفين لكنه ارتفاع في المنطقة المركزية. وفي هذا السيناريو نرى أن منحنى الخسارة الكلي يصبح مسطحًا إلى حد ما، إذ تبقى العظمى باستمرار عند مستوى . وعند هذه النقطة، لا نتوقع أن تنخفض الخسارة الكلية انخفاضًا ملحوظًا باستخدام أكثر انحدارًا.
قد يلاحظ المرء الشكل المتعرج لمنحنيات الخسارة الفردية في الشكل 3؛ وبالتحديد، توجد قمم (وقيعان) على بعد يقارب () من مركز الرنين. وفي الواقع، يعتمد مخطط منحنى الخسارة بحساسية على توزيع بيانات التدريب. فالطبقة الأولى من ANN تحتوي على مجموعة من مرشح التفاف تعمل أساسًا وفق توزيع البيانات المحلي. ويعني الشكل المتعرج أن توزيع البيانات المحلي المطلوب ينبغي أن يكون مختلفًا بعض الشيء عن المعطى في الجدول 1. وعلى نحو أدق، ينبغي أن تكون كثافات أعداد عينات التدريب في جوارات القمم أعلى. وهناك سمة أخرى في الشكل 3، إذ نرى أن القمم تصبح أعرض مع توزيع عددي أشد انحدارًا لعينات التدريب. وبالنظر إلى المنطقة -، وبسبب الأكبر، تمتلك Train \@slowromancapiii@ عينات تدريب أقل من Train \@slowromancapi@ و Train \@slowromancapii@. ولذلك تؤدي العينات غير الكافية إلى خسائر أعلى في هذه المنطقة، كما يبيّنه اتساع قمة المنحنى الأحمر. ومع ذلك، وبما أن الخسارة الكلية مقبولة، فلن نزيد ضبط التوزيع المحلي لبيانات التدريب.
4.1.1 التنبؤ بزاوية الرنين وسعة الرنين
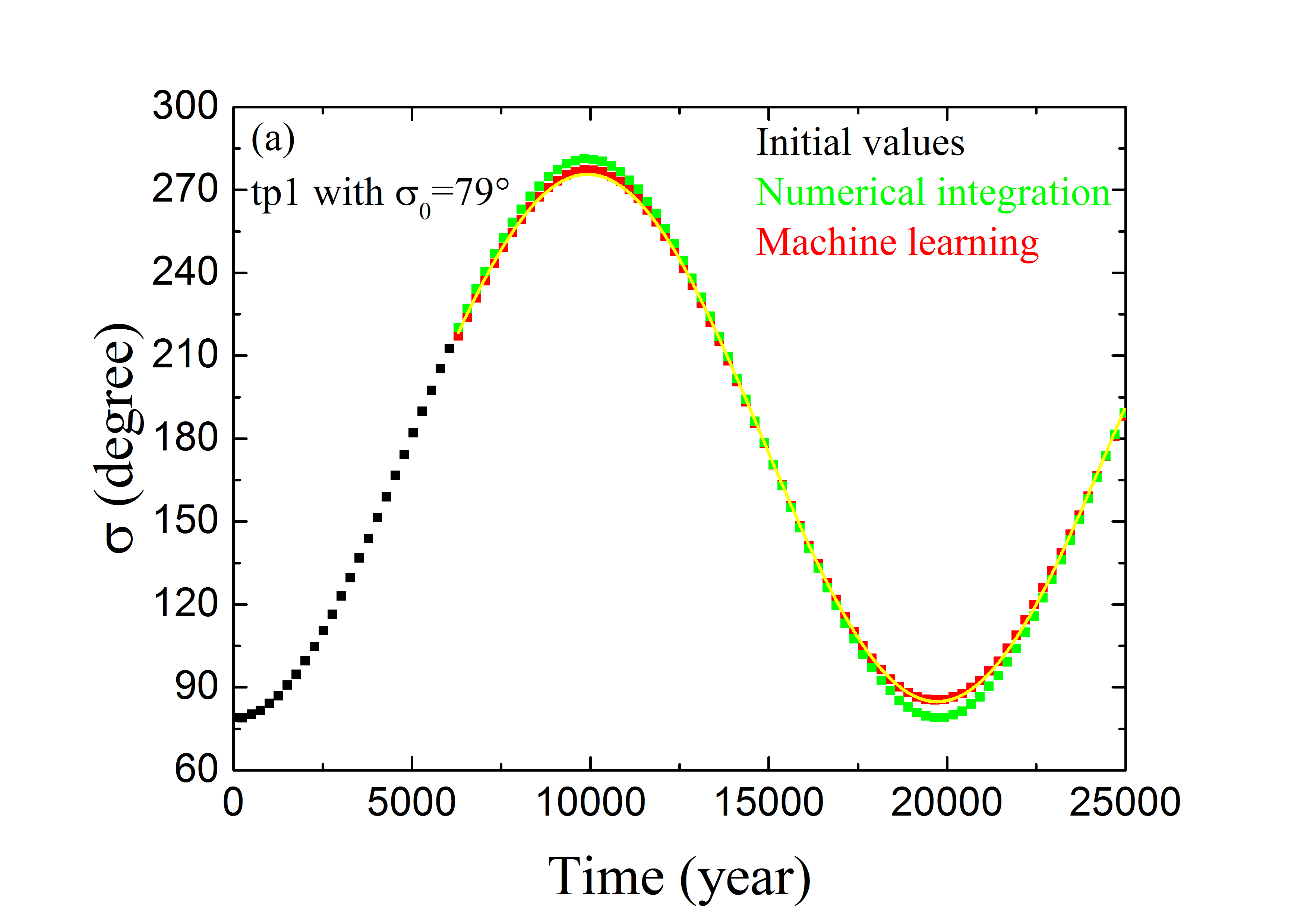
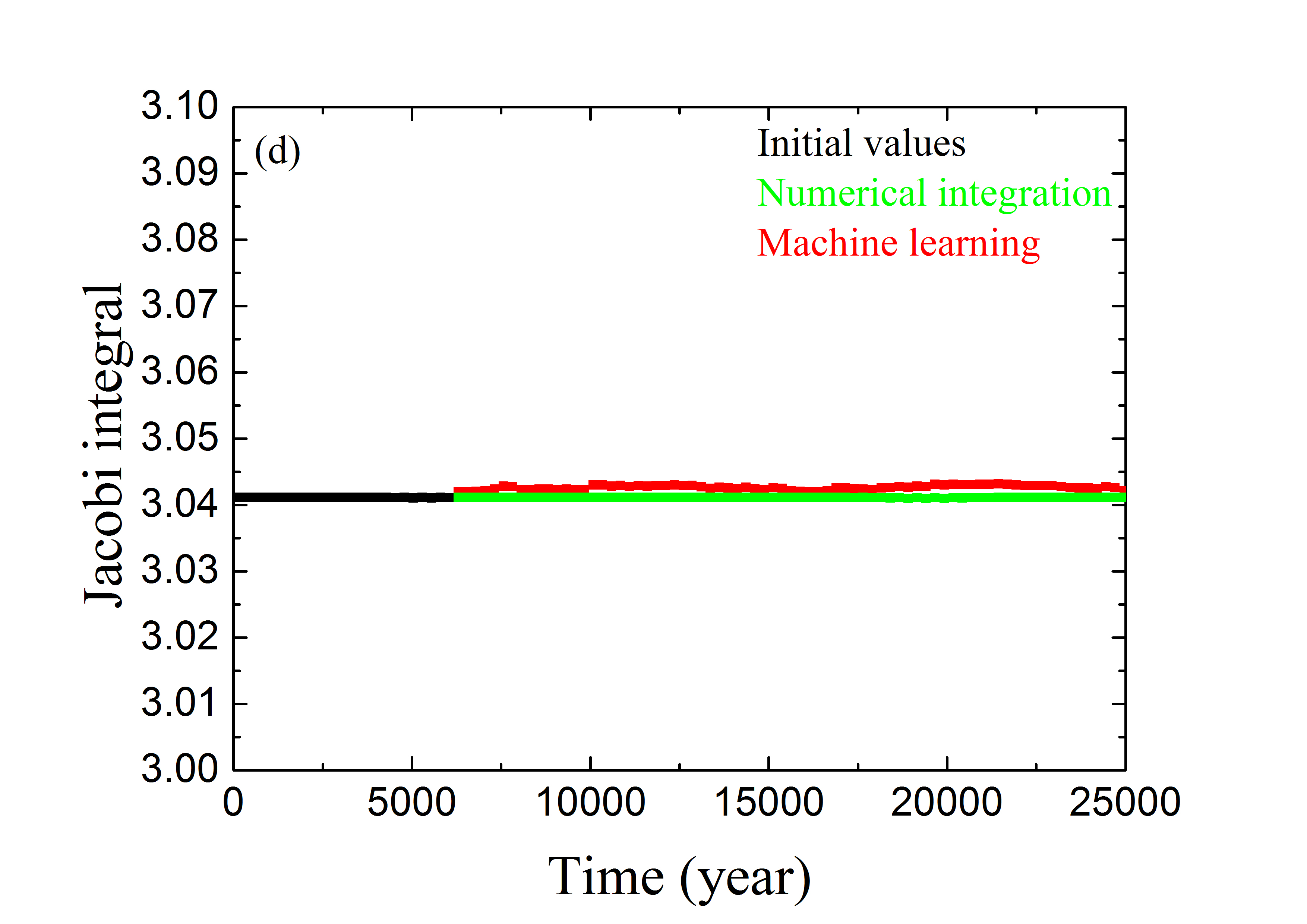
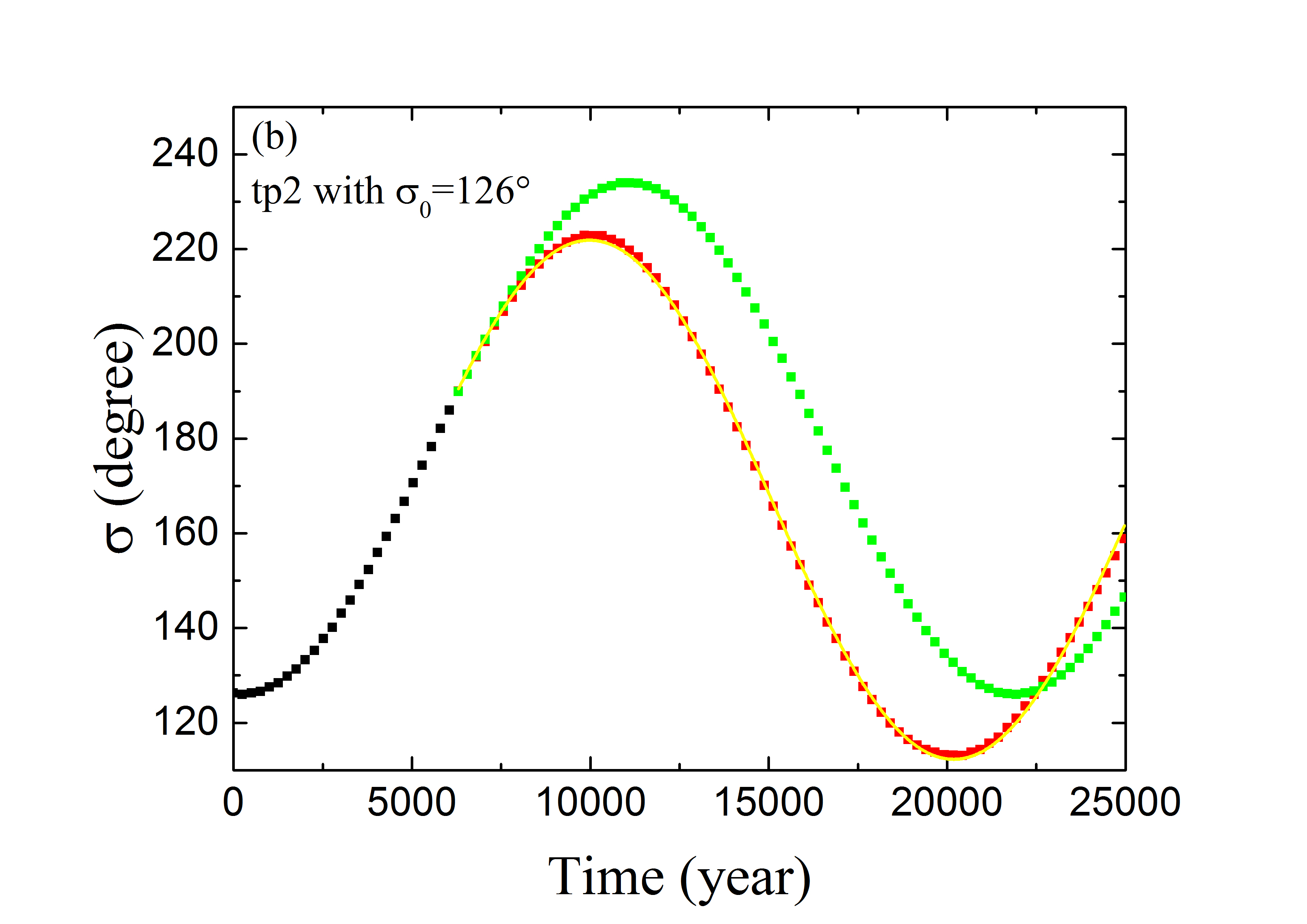
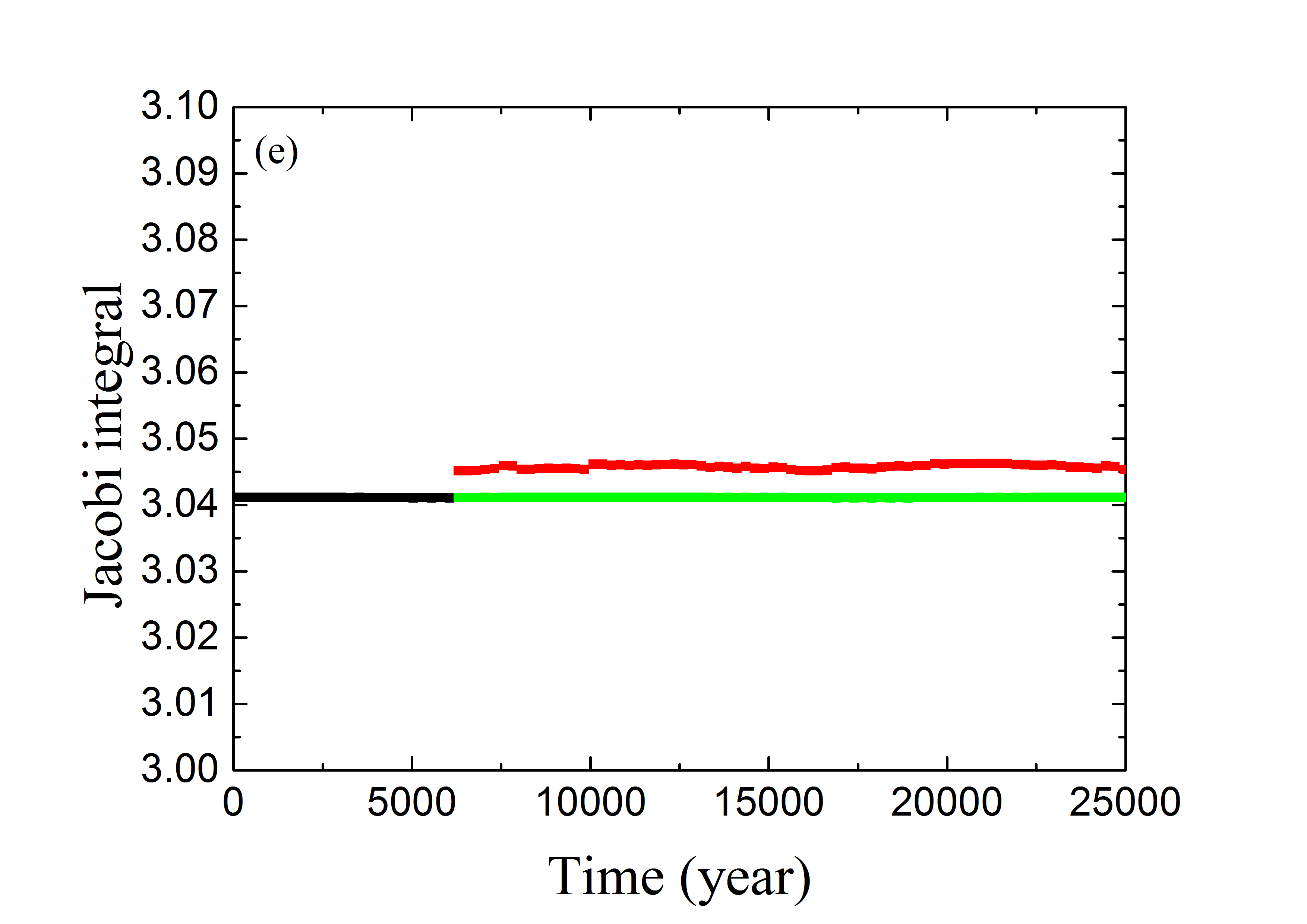
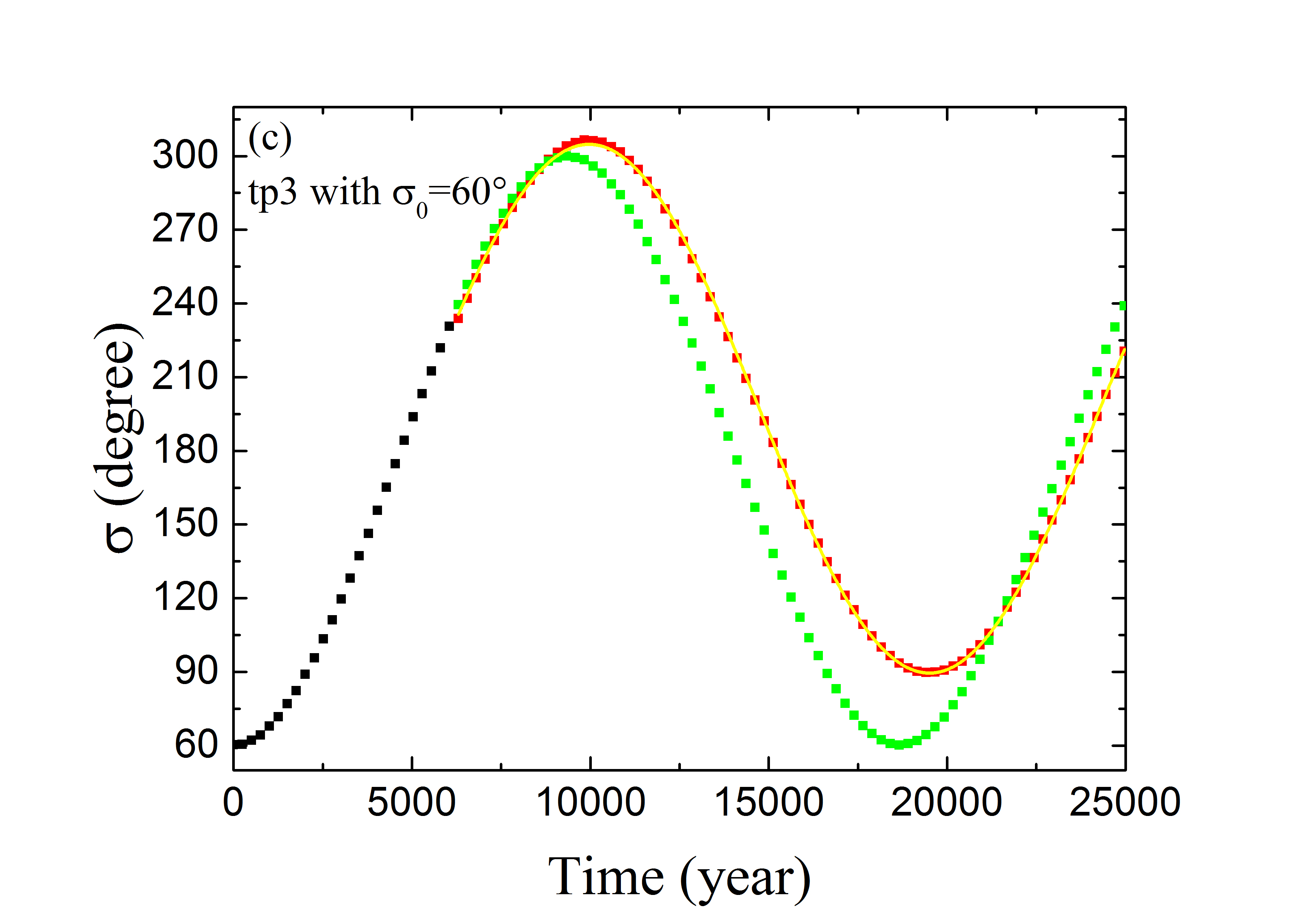
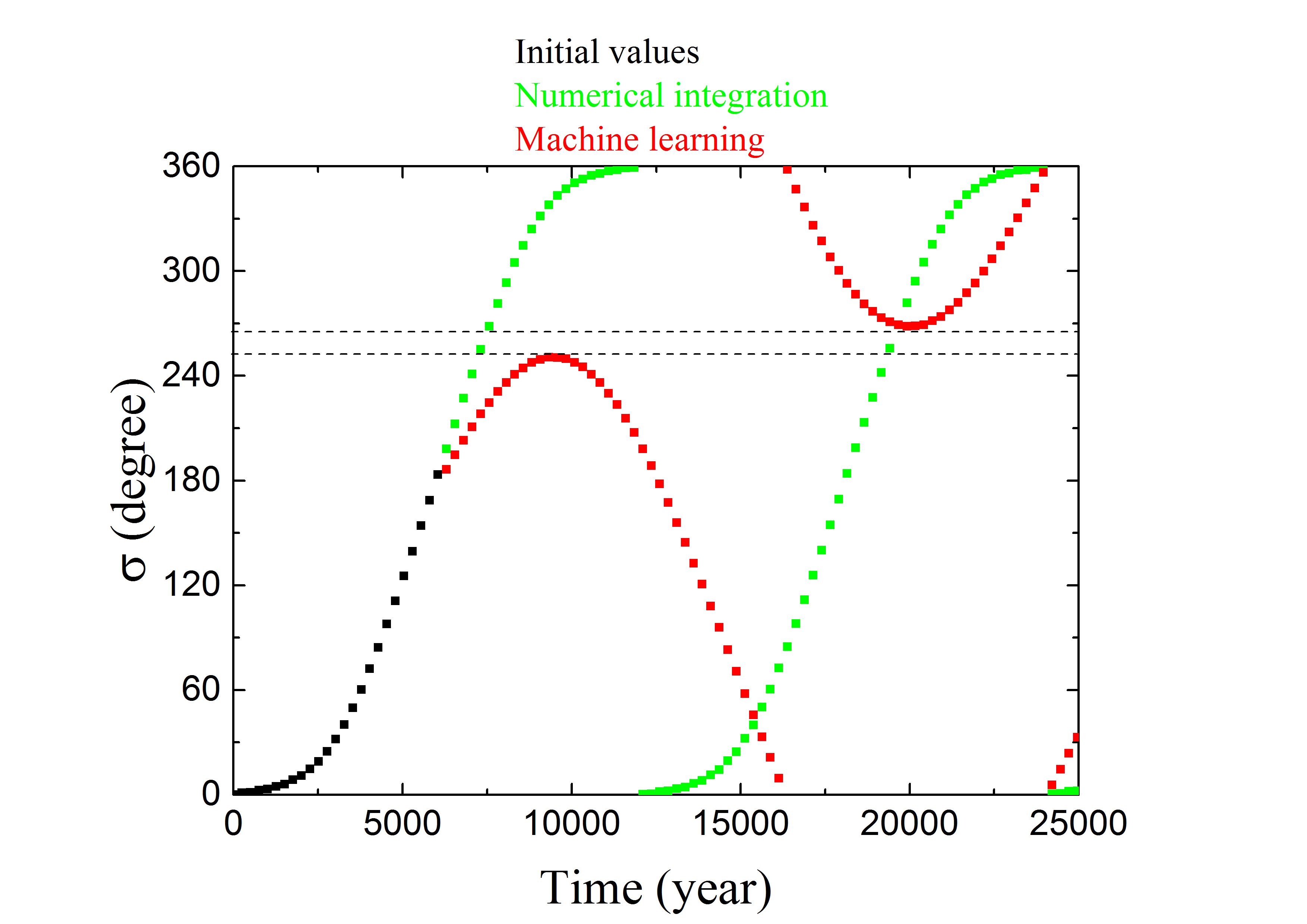
لعرض أداء ANN المدرّبة بالمجموعة Train \@slowromancapiii@، نعرض في الشكل 4 التنبؤ المداري لثلاثة أمثلة ممثلة من مجموعة التحقق. يسرد العمود الأيسر التطور الزمني لزاوية الرنين ، وهو ما يمكن أن يتحقق من آثار تنبؤ ANN بالزاويتين المداريتين و . أما بالنسبة إلى الجسيم tp1 الذي يبدأ بزاوية الرنين ، فإنه يحقق الخسارة الدنيا (انظر المنحنى الأحمر في الشكل 3). ويُعرض تطور لهذه العينة في الشكل 4a. وتمثل النقاط السوداء قيم في أول سنة بوصفها الشروط الابتدائية لطريقة تعلم الآلة. وللأعوام التالية ، تتنبأ ANN المدرّبة بقيم المتطورة (النقاط الحمراء)، وتُحسب بالتكامل العددي (النقاط الخضراء). ويبدو أن الحلين يتطابقان تمامًا. غير أن أداء ANN المدرّبة قد يكون ضعيفًا نسبيًا للجسيمين tp2 ذي و tp3 ذي ، إذ لهما أكبر خسائر مقدارها (انظر الشكل 3). وتعرض الأشكال 4b و 4c تطور زاويتي الرنين لـ tp2 و tp3، على التوالي. ويمكن ملاحظة أن قيم المحصلة من التكامل العددي (بالأخضر) وتنبؤ تعلم الآلة (بالأحمر) قد تختلف اختلافًا معتدلًا من وقت إلى آخر. وترجع هذه المسألة إلى الخسائر الكلية الحالية التي لم يعد من الممكن تقليلها في ANN المصممة. وقد تكون بعض الاعتبارات الخاصة ببنية ANN مفيدة لزيادة تحسين قدرة تعلم الآلة على التنبؤ بالمسارات الرنانة. وسنعود إلى ذلك في مناقشة هذه الورقة.
ومع ذلك، ولغرض تحديد الحالة الرنانة، لا نحتاج إلا إلى قياس الانحراف الأعظمي لـ عن مركز الرنين، أي سعة الرنين . وعندئذ يمكن اعتبار الجسيم مستقرًا في MMR 2:3 إذا كانت ، وقد يكون هذا المعيار أقل اعتمادًا على خطأ عند زمن محدد. وكما هو مبين في الشكلين 4b (لـ tp2) و 4c (لـ tp3)، على الرغم من وجود فرق طور واضح بين المنحنيين الأخضر (من التكامل العددي) والأحمر (من تعلم الآلة)، فإن سعتي هذين المنحنيين الشبيهين بالجيب (المكافئتين لـ ) قد تكونان متقاربتين. ثم نحدد لكل عينة من جميع عينات مجموعة التحقق البالغ عددها 1000 قيمة من تطور إجمالي مدته 25000 سنة. واختيار هذا المقياس الزمني معقول لأنه أطول من الفترة النموذجية لدورة تأرجح كاملة. ومن أجل قياس سعة التأرجح على نحو أفضل، أجرينا ملاءمات جيبية للنقاط المنفصلة (الحمراء) بدلًا من استخدام النقطة ذات الانحراف الأعظمي. وفي الأشكال 4a-4c، يُرسم الجيب الأفضل ملاءمة بوصفه المنحنى الأصفر، وتُشتق السعة تبعًا لذلك من إجراء الملاءمة.
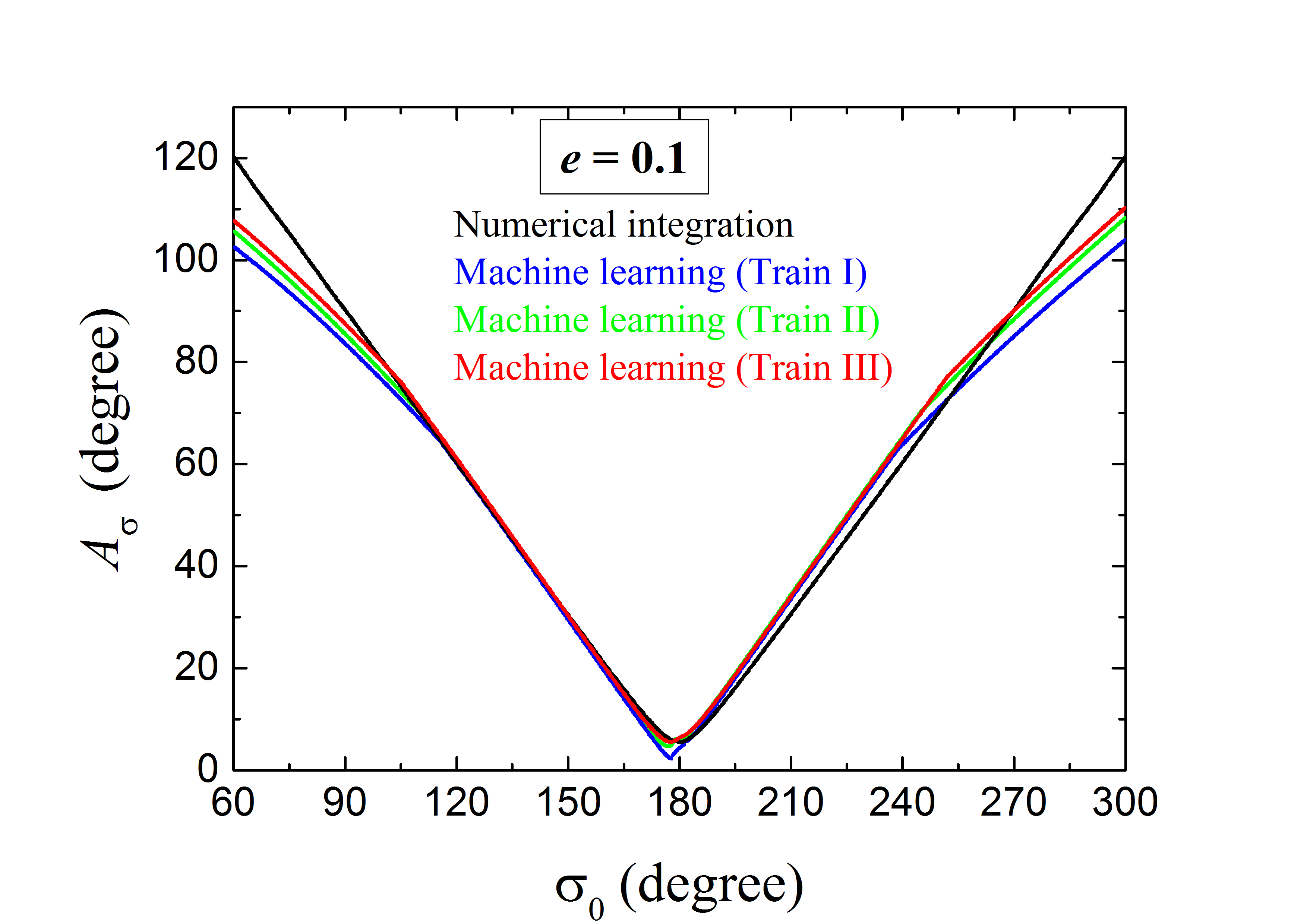
يعرض الشكل 5 سعات الرنين لجسيمات التحقق، المستحصلة بالتكامل العددي (أسود)، وبـ ANNs المدرّبة بمجموعات التدريب Train \@slowromancapi@ (أزرق)، و Train \@slowromancapii@ (أخضر)، و Train \@slowromancapiii@ (أحمر). ومن المثير للاهتمام أن نلاحظ أنه، للمدارات ذات في المنطقة المركزية حول مركز الرنين عند ، يوجد تطابق شبه كامل بين المتنبأ بها والحقيقية. ونلاحظ كذلك أن منحنيات تعلم الآلة تقع قليلًا فوق منحنى الطريقة العددية عند -، في حين تبدو مطابقتها أفضل في الجانب الآخر -. ويبدو أن الآلة لم تتعلم الخاصية التناظرية لـ MMR 2:3 بالنسبة إلى مركز الرنين عند ، كما هو معروض في الشكل 1. والسبب المحتمل هو أن الالتفافات المدمجة في ANN تركز على كل عنصر في مجموعة البيانات، وهي ليست متناظرة تمامًا. ومع ذلك، يمكن إهمال عدم التناظر هذا عندما تُطبق ANN المصممة لتحديد الأجسام الرنانة.
إلى جانب ذلك، نرى في الشكل 5 أن دقة التنبؤ تصبح أدنى عند أي من حافتي منطقة الرنين المستقرة هذه. ففي المناطق البعيدة عن مركز الرنين، أي عند و ، تبلغ الفروق النسبية بين منحنيات تعلم الآلة والتكامل العددي %. وعند هذه النقطة، يمكن لـ ANN المدرّبة أيضًا أن تقدم قابلة للمقارنة وأصغر بعض الشيء من . وبالتالي ستظل الجسيمات المرتبطة بها مصنفة على أنها رنانات 2:3 مستقرة. وبإلقاء نظرة أدق على مخططات ، نجد أن حالة Train \@slowromancapi@ تؤدي أداءً ضعيفًا نسبيًا، بينما تبدو حالة Train \@slowromancapiii@ الأفضل أداءً، كما يُقيّم من أداء ANN عند أكبر قيم . وهذه النتيجة متسقة مع مناقشتنا السابقة لمخططات الخسارة لهذه الحالات الثلاث في القسم 3.3. ومن الآن فصاعدًا، سيُشار إلى ANN المبنية من Train \@slowromancapiii@ باسم ”أفضل ANN مدرّبة”، وستُطبق على الأجسام الرنانة ذات العناصر المدارية المتنوعة.
لتقييم أداء أفضل ANN مدرّبة بصورة إضافية، يسرد العمود الأيمن من الشكل 4 التطور الزمني لتكامل ياكوبي لعينات التحقق tp1 و tp2 و tp3. وللألوان المعاني نفسها كما في العمود الأيسر. وبدلالة و ، يمكن التعبير عن قيمة كما يلي
| (7) |
ونلاحظ أن التقريبية هذه تختلف عن الدقيقة في المعادلة (4) فقط برتبة . ومن ثم يمكن استخدام قيم للتحقق من التنبؤ بالعنصرين المداريين الآخرين و . ونجد أنه، لأي من الأمثلة الرنانة الثلاثة، يكون تغير المتنبأ بها (النقاط الحمراء) عند نقاط زمنية مختلفة صغيرًا للغاية، من رتبة 0.2%. وعلى الرغم من أن المتنبأ بها قد تكون منفصلة قليلًا عن الوسوم (النقاط الخضراء)، فإن حفظ تكامل ياكوبي يتحقق جيدًا.
4.1.2 التعميم على الحالة غير الرنانة
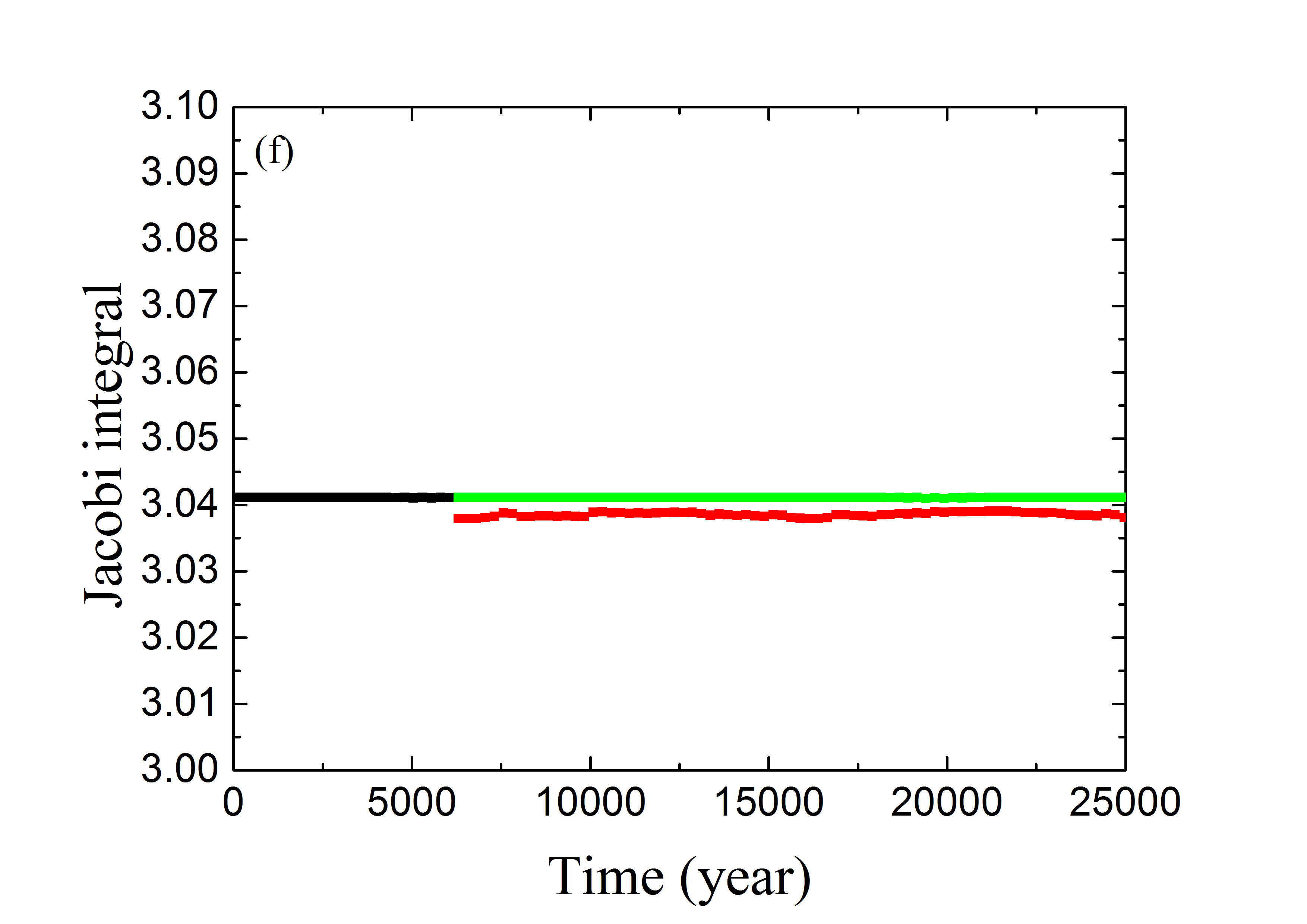
بعد النظر في الأجسام الرنانة، ننتقل الآن إلى فحص مظهر جسم غير رنان عندما يمر عبر أفضل ANN مدرّبة لدينا. لقد ولّدنا بعض الأجسام غير الرنانة في مجموعة التحقق، بإعطائها ، مع إبقاء المعلمات المدارية الأخرى كما هي. وفي التكامل العددي، تُصنف هذه الأجسام بأنها غير رنانة لأن زوايا رنينها تدور أثناء التطور. ويُقدم مثال في الشكل 6. وبالنظر إلى القيم الابتدائية (بالأسود)، نعرض تطور اللاحق من التكامل العددي (بالأخضر) وتنبؤ تعلم الآلة (بالأحمر). ويمكن ملاحظة أن المتنبأ بها تصل فعلًا إلى القيمة ، وهي تبعد عن مركز الرنين، مما يشير إلى سعة رنين وفق التعريف المعتاد. ولذلك فإن أفضل ANN مدرّبة لدينا قادرة أيضًا على تصنيف الجمهرة غير الرنانة بفعالية.
قد يلاحظ المرء في الشكل 6 أن المتنبأ بها (المنحنى الأحمر) ليست دائرية تمامًا، إذ توجد فجوة ضيقة بين و ، كما يشير الخطان المتقطعان. وتظهر القمة المحلية لـ عند زمن يقارب 10000 سنة، وهو قريب من نصف فترة تأرجح الرنين 2:3. وفي هذه اللحظة، يتحول تطور إلى الانخفاض، خلافًا للسلوك الواقعي (الدائري) الذي يمثله المنحنى الأخضر الآخذ في الازدياد. ويرجع هذا التحول في المخطط إلى أن المسارات الرنانة وحدها استُخدمت لتدريب ANN، وهي تجعل غير الرنانة تتصرف بطريقة مشابهة، أي إن الزيادة الرتيبة لـ ينبغي ألا تستمر مدة أطول من نصف فترة الرنين 2:3 (انظر الشكل 4). ومع ذلك، وكما قلنا أعلاه، فإن المعيار المعتاد الذي يحدد غير الرنانات ذات لن يتأثر إطلاقًا.
4.2 حالات و الأكبر
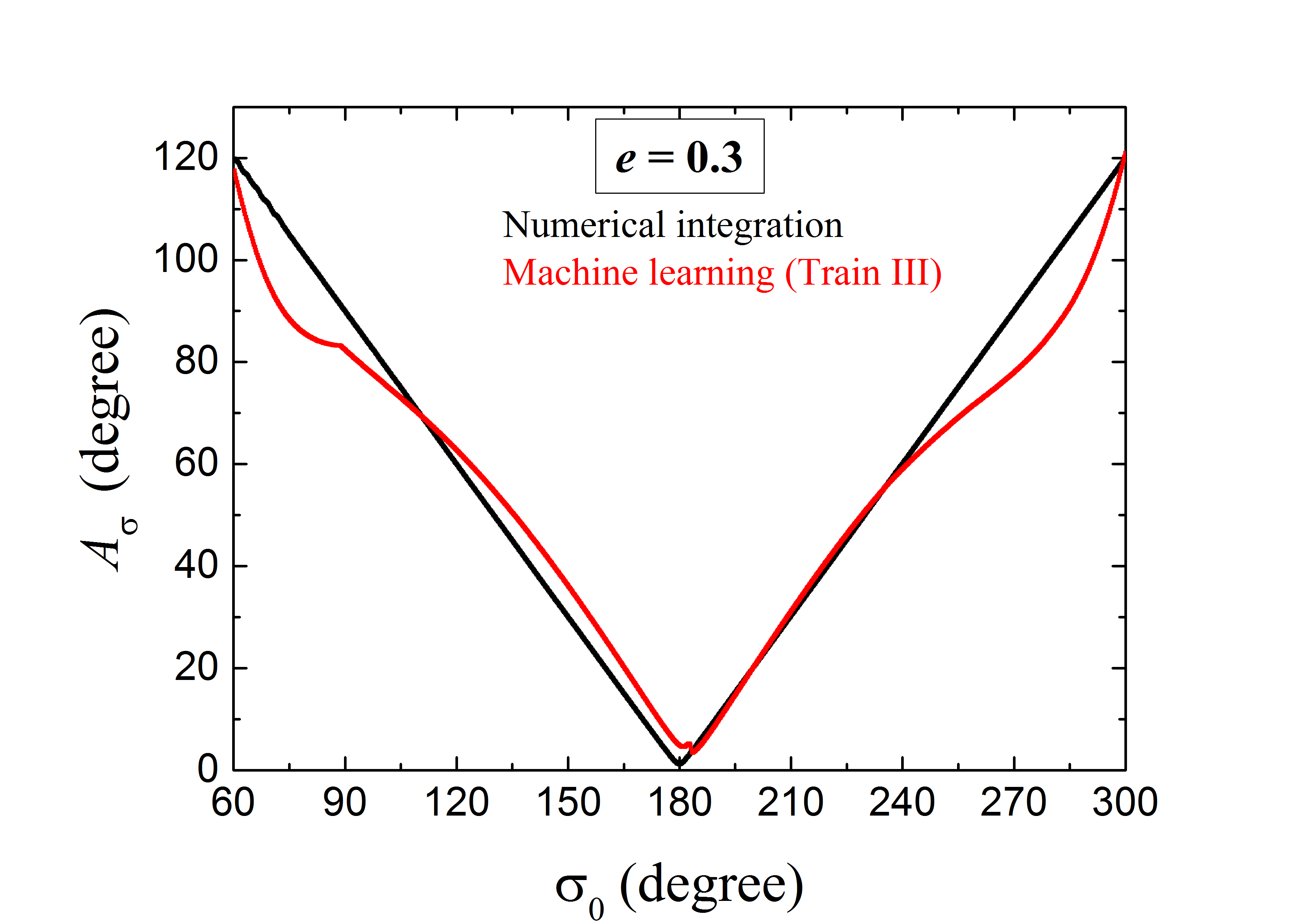
كما هو مبين أعلاه، تستطيع أفضل ANN مدرّبة لدينا أن تتنبأ جيدًا بالحالة الرنانة للمسارات ذات الشذوذ المركزي الصغير . ومن الأهمية الكبيرة أيضًا بحث ما إذا كان يمكن تطبيق نموذج ANN هذا على الحالات الأعلى شذوذًا. وحتى الآن، رُصد جزء كبير من KBOs الرنانة 2:3 على مسارات ذات كبير، يصل إلى نحو 0.3.
بالنسبة إلى عينات التدريب والتحقق، لمجموعة المعلمات الابتدائية القيم نفسها كما في حالة ، لكن شذوذاتها المركزية تُضبط على القيمتين التمثيليتين الأخريين و . ثم أعدنا تدريب أفضل نموذج ANN، الذي يتضمن كثافة عددية لعينات التدريب على صورة (أي Train \@slowromancapiii@، انظر الجدول 1). وأثناء عملية التدريب، وجدنا أن خسائر التدريب لا تزال تنخفض بمعدل مشابه لما سبق. وبعد معالجة 3000 حقبة تدريبية، لا تكاد خسائر التدريب تنخفض ولا تبدو خسائر التحقق آخذة في الازدياد. لذلك نقيم أيضًا أداء ANN المحصلة على مجموعة التحقق عند الحقبة 3000.
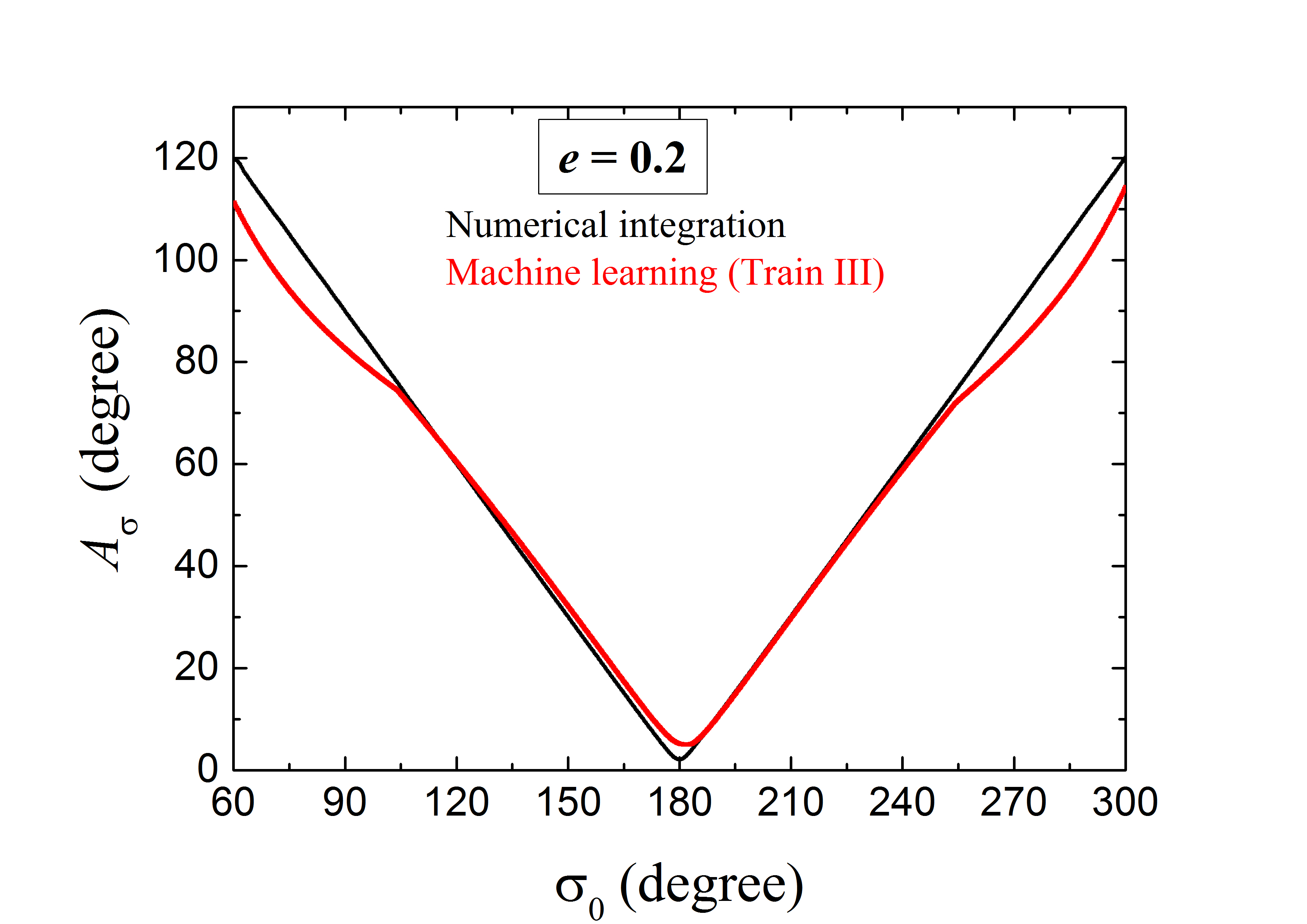
يعرض الشكل 7 والشكل 8 النتائج لجسيمات التحقق ذات و ، على التوالي. ونلاحظ أن المخططات الإجمالية لسعات الرنين المتنبأ بها بواسطة ANN (المنحنى الأحمر) والمحسوبة من التكامل العددي (المنحنى الأسود) تبدو متشابهة. وبالمقارنة مع حالة (انظر المنحنى الأحمر في الشكل 5)، يلاحظ المرء على الفور ما يأتي: (1) يمكن تحديد جميع الرنانات المستقرة 2:3 ذات بفعالية بطريقة تعلم الآلة. (2) وبالمثل، يمكن أن يكون تنبؤ تعلم الآلة بـ دقيقًا جدًا للمدارات الرنانة ذات الصغير إلى المتوسط، أي ذات . (3) وعند الكبير، قد تنشأ فروق نسبية معتدلة لكنها قابلة للمقارنة بين المنحنيين المتنبأ به والعددي، عند مستوى 10%-15%. وكما قلنا من قبل، يعود هذا الخطأ إلى قلة المعلومات للجسيمات الأبعد عن مركز الرنين.
غير أنه في منطقة الرنين عند الكبير، تكون مخططات المتنبأ بها غير متشابهة إلى حد ما من أجل قيم المختلفة. وبالنظر إلى تناظر منحنى ، نكتفي بدراسة جسيمات التحقق ذات ، أي الواقعة في أقصى الجزء الأيسر في الأشكال 5 و 7 و 8. ولغرض الوضوح، سيرمز إلى الفارق في بين تنبؤ تعلم الآلة وحساب التكامل العددي عند محددة بـ . وفي حالات و و ، تبلغ قيم العظمى و و ، على التوالي. ويبدو أن أسوأ تنبؤ يأتي من المدارات الأعلى شذوذًا. وعلى العكس من ذلك، عندما ننظر إلى الطرف الأيسر من منحنى (أي )، نجد أن جسيم التحقق ذي لديه أدق تنبؤ لـ . وإجمالًا، إذا نظرنا إلى كامل المنطقة -، فإن القيم المتوسطة للفروق النسبية في تكاد تكون نفسها، أي 5%-9% تقريبًا من أجل 0.1-0.3. وبناءً على ذلك، نرى أن القدرات العامة لـ ANNs المدرّبة قد تكون متشابهة في التنبؤ بسلوكيات تأرجح الجسيمات ذات قيم مختلفة. وفي الواقع، فحصنا الخسائر الكلية على مجموعات التحقق الكاملة في حالات و و ، ووجدنا أن قيمها من رتبة المقدار نفسها.
وباختصار، تشير نتائجنا إلى أن طريقة تعلم الآلة يمكن أن تحدد بفعالية الحالة الديناميكية للجسيمات، سواء كانت رنانة مستقرة أم غير رنانة، بتكلفة حاسوبية أدنى بكثير من تكلفة التكامل العددي. وقد يساعد تطبيق ANN المدرّبة في غربلة عدد هائل من KBOs المتوقع اكتشافها في المستقبل القريب، واختيار جزء صغير منها بوصفه مرشحات رنانة، ثم تُؤكد لاحقًا بالتكاملات العددية. ويمكن لهذا الإجراء أن يقلل زمن الحوسبة اللازم لتصنيف KBOs الرنانة تقليلًا كبيرًا.
5 الاستنتاجات
حاولت بعض الأعمال الحديثة جدًا استخدام تعلم الآلة لحل الأنظمة الهاملتونية القابلة للتكامل (Greydanus, Dzamba & Yosinski, 2019) ومسألة الأجسام 3 العامة (Breen et al., 2020). فالحالة الأولى تحتوي جوهريًا على حركة منتظمة فقط، وادُّعي أن ANN المدرّبة قادرة على التنبؤ بديناميكيات دقيقة على امتداد زمني طويل، في حين تنطوي الحالة الثانية على حركة فوضوية؛ ومن ثم تعتمد دقة تنبؤ ANN اعتمادًا قويًا على زمن تطور النظام، الذي ينبغي أن يكون محدودًا جدًا. وفي هذه الورقة، نبحث أداء تنبؤات تعلم الآلة لسلوك MMR 2:3 في نموذج PCR3BP الخاص بالشمس+نبتون+جسيم. وعند الشذوذ المركزي الصغير ، يُظهر الرنان 2:3 حركة منتظمة في النظام غير القابل للتكامل، وهو ما يمكن عده حالة وسيطة. وبالنظر إلى استقرار KBOs الرنانة 2:3 الواقعية، لا نأخذ في الحسبان إلا العينات ذات سعات الرنين (Li, Zhou & Sun, 2014).
وبتوفير بيانات المسار على مدى فاصل زمني سنة بواسطة التكامل العددي، دربنا ANN على تعلم سلوك الجسيمات في MMR 2:3 مع نبتون. وفي التعلم الخاضع للإشراف، تمكنا من تصميم نمط مناسب لمجموعة التدريب (أي Train \@slowromancapiii@ في الجدول 1) وشبكة ANN تحتوي على طبقات التفاف وطبقات تامة الاتصال. وتبيّن نتائجنا أنه باستخدام البيانات الابتدائية في أول سنة، تستطيع أفضل ANN مدرّبة التنبؤ بمسارات الرنانات 2:3 خلال السنوات اللاحقة . أما بالنسبة إلى زاوية الرنين المتطورة ، فيبدو أن تنبؤ تعلم الآلة وحساب التكامل العددي يتطابقان على نحو جيد، وقد تكون الأخطاء النسبية صغيرة إلى حد بضع درجات فقط. إضافة إلى ذلك، فإن تكامل ياكوبي المتنبأ به، بوصفه دالة في نصف المحور الرئيسي المداري والشذوذ المركزي، قد يكون محفوظًا جيدًا أيضًا.
وإلى جانب التنبؤ بالمدار، نهدف إلى تحديد الرنانات المستقرة 2:3 بقياس سعة الرنين . وبجمع بيانات 6250 سنة المعطاة وبيانات 18750 سنة المتنبأ بها، نحصل على المتطورة على مقياس زمني إجمالي قدره 25000 سنة، وهو أطول من دورة تأرجح كاملة لـ MMR 2:3. ونجد أن أفضل ANN مدرّبة المذكورة تستطيع تصنيف الجمهرة الرنانة ذات في مجموعة التحقق بفعالية وبمستوى ثقة عال جدًا. ثم طُبق نموذج ANN لدينا على الرنانات 2:3 الواقعة على مدارات أكثر شذوذًا ذات تصل إلى 0.3، وظلت طريقة تعلم الآلة تعمل جيدًا جدًا في التنبؤ بسعات رنينها .
وفي الختام، نقترح أن طريقة تعلم الآلة قد تكون نهجًا سريعًا في تحديد الحالة الديناميكية للأجسام في MMR 2:3 المستقرة مع نبتون. وبهذه الطريقة، يمكننا توفير ما يصل إلى من زمن الحوسبة مقارنة باستخدام التكاملات العددية. وبفضل هذه الميزة، قد ينتج تعلم الآلة بسرعة مجموعة أولية من الرنانات المرشحة للتصنيف الديناميكي لـ KBOs الواقعية. وبالتأكيد، ما زال يلزم عمل أكبر بكثير لتطوير ANN بصورة عملية أكثر.
6 المناقشة
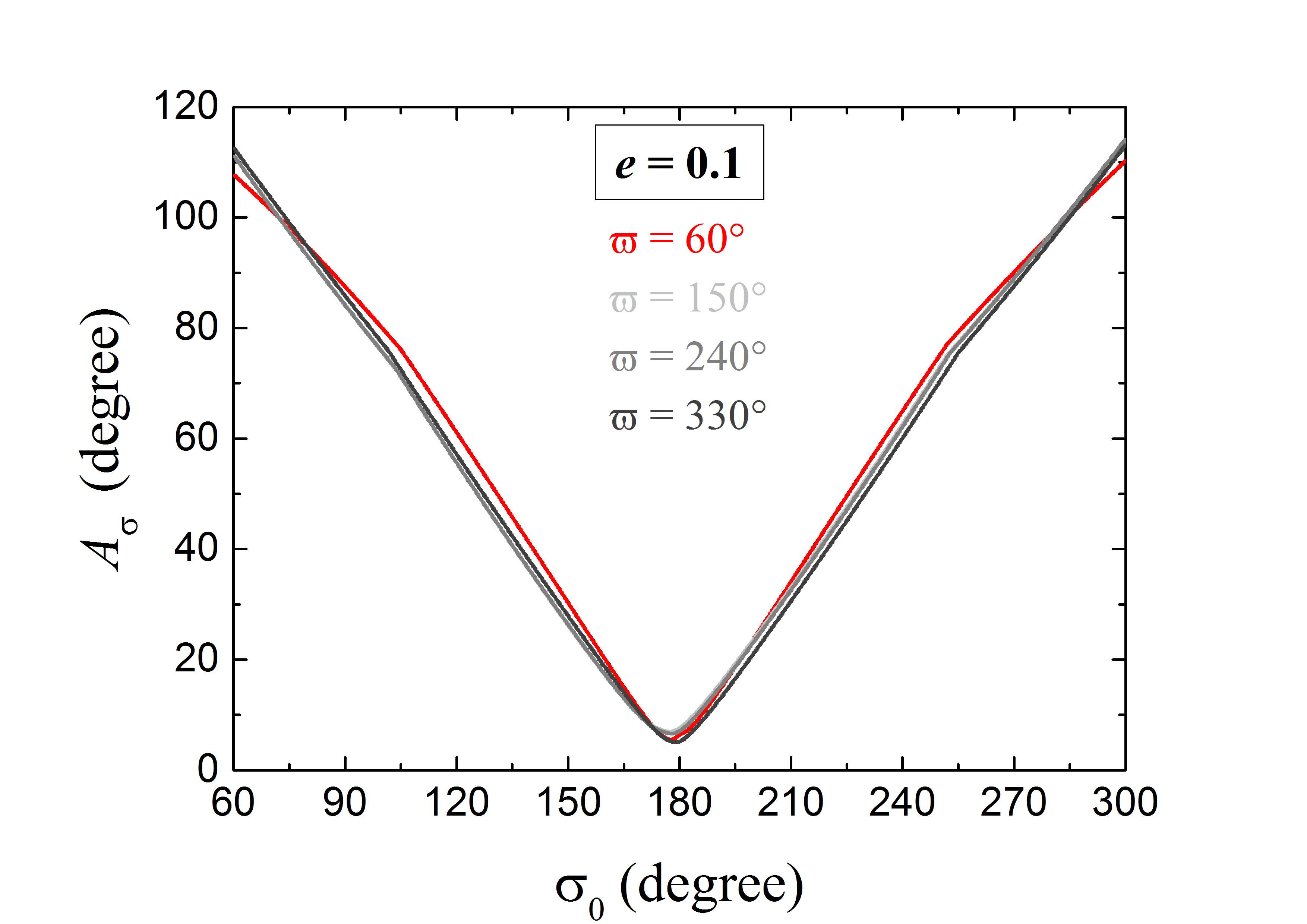
يوجد تساؤل بشأن بناء أفضل ANN مدرّبة لدينا، أي اختيار خط طول الحضيض . وكما هو موصوف في المعادلة (5)، عندما تثبت ، تكون زاوية الرنين مكافئة لأخذ عينات من خط الطول المتوسط للجسيم، لأن خط الطول المتوسط لنبتون يساوي ابتدائيًا 0. فهل يمكن لتوسيع أخذ عينات أن يترك آثارًا في نتائجنا الرئيسة؟ من أجل تقييم الأثر المرتبط بذلك صراحة في تنبؤ تعلم الآلة بـ ، نجري هنا تشغيلات إضافية تبدأ بقيم متميزة لـ . وبعد أن نظرنا سابقًا في ، نختار ثلاث قيم إضافية لـ : و و . وهذه القيم الأربع ممثلة لأنها موزعة بانتظام في كامل المنطقة . وفي حالة ، أعدنا تدريب أفضل ANN مرتبطة بـ Train \@slowromancapiii@. وتُعرض هذه النتائج في الشكل 9. والمنحنى الأحمر في الشكل 9 مستخرج من الشكل 5، ويشير إلى المقدرة سابقًا بواسطة ANN من أجل . أما المنحنيات الرمادية فتقابل القيم الثلاث الأخرى لـ ، وقد وجد أنها تكاد تتراكب مع المنحنى الأحمر. ومن ثم لن تتأثر بنية نموذج ANN لدينا باختيار . وهذه النتيجة متسقة مع ما حاججنا به نظريًا في القسم 2.2، أي إن اختيار قيمة اعتباطية لـ لبناء ANN أمر معقول. ونتيجة لذلك، ما دامت مأخوذة العينات بكثافة في النطاق من 0 إلى ، فقد نستطيع تدريب ANN أعم. غير أنه، وبسبب القيود الحاسوبية، ليس من السهل حاليًا إنجاز هذه المهمة.
لاحظنا في الشكل 4 أنه على الرغم من أن تكامل ياكوبي المتنبأ به يكاد يكون محفوظًا، فإن الفارق الصغير عن حساب التكامل العددي قد يكون جانبًا محتملًا لتحسين ANN. وينبغي التنبيه إلى أن PCR3BP هي في الواقع نظام هاملتوني، وأن تكامل ياكوبي يسمى أحيانًا تكامل الطاقة النسبية. ويمكن استخدام هذا الحفظ لتحسين دقة التنبؤ، كما فعل Breen et al. (2020) في مسألة الأجسام 3 العامة. فقد أضافوا طبقة إسقاط لتحسين حفظ الصفة الهاملتونية أثناء تدريب ANN. وتضبط هذه الطبقة الإحداثيات بتصغير معلمة مرتبطة بخطأ الطاقة. وبالمثل، يمكن تطبيق مراعاة كمية محفوظة أيضًا على دراسة أنظمة ديناميكية أخرى بواسطة ANNs. بل تقترح مطبوعة جديدة أن خوارزمية تعلم الآلة، باستخدام بيانات المسارات من أنظمة ديناميكية مجهولة، يمكن أن تكتشف تلقائيًا الكميات الفيزيائية المحفوظة (Liu & Tegmark, 2021).
في إطار PCR3BP ذات درجتي حرية، تمتلك الحركة الرنانة ترددين أساسيين. يقابل أحد الترددين معدل تغير زاوية الرنين، أي . أما التردد الآخر، الذي يشير إلى التطور العلماني، فيرتبط بمعدل تغير خط طول الحضيض، أي . وفي مرحلة المعالجة المسبقة للبيانات، وبوصفها مكونًا من ANN، قد نستخدم نواة الالتفاف مرشحًا لإيجاد هذين الترددين الرئيسيين بمستوى عال إلى حد ما من الدقة. وبسبب الاضطراب الناجم عن نبتون، لا تزال الحركة الرنانة تحتوي على حدود إضافية ذات ترددات أعلى بكثير، يرمز إليها بـ . والآن، إذا طلبنا دقة كلية تقارب ، فنحتاج فقط إلى الحصول على الترددين المنخفضين و بدقة ، وهذا قابل للتحقيق. أما إذا رغبنا في أن تبلغ الدقة الكلية ، فعلينا جعل ANN تتعلم بكفاءة سلوك الحركة المرتبط بالترددات الأعلى . ونفترض أن المعالجة المسبقة باستخراج الترددات الأساسية قد تساعدنا على زيادة خفض الخسارة على مجموعة التحقق وزيادة دقة التنبؤ.
حتى الآن، بحثنا ما إذا كان بوسع ANN تعلم حركة الأجسام الرنانة 2:3 ”الاصطناعية”. وبالمثل مع المناهج المعتادة، نظرنا أولًا في الحالة المستوية التي تتطلب قدرة حاسوبية أدنى. ولا يمكن تطوير طريقة تعلم الآلة وتعميمها لاحقًا على KBOs الواقعية، مثل الأجسام على مدارات مائلة، إلا إذا وُجد أنها فعالة. وبناءً على ذلك، ينبغي إدراج الميل المداري والعقدة الصاعدة في نموذج ANN. ولإضافة بعدين آخرين في بيانات التدريب، نحتاج إلى تدريب ما لا يقل عن مدارًا للحفاظ على دقة التنبؤ الحالية. وفي فضاء البيانات الأعلى أبعادًا، يصبح فرط الملاءمة أكثر احتمالًا، وقد يواجه تحسين الانحدار التدرجي مشكلات أيضًا. ويظهر تحد مشابه في تصنيف الفيديو، إذ يتعامل المرء مع صور عالية الأبعاد. وقد يكون إضافة عدة طبقات دمج مختلفة استراتيجية ممكنة (Karpathy et al., 2014). وقد تكون المواءمة النظامية (Sirimongkolkasem & Drikvandi, 2019)، أو التعلم الآلي المؤتمت من Microsoft على Azure11 1 https://docs.icrosoft.com/en-us/azure/machine-learning/concept-manage-ml-pitfalls، إمكانات إضافية. ومن المهم الإشارة إلى أن بنية نموذج ANN تعتمد اعتمادًا قويًا على توزيع البيانات. وبما أن بيانات 6-بعدية مطلوبة لوصف المسارات المائلة، فقد تكون بنية الشبكة مختلفة تمامًا عن تلك التي حصلنا عليها. وخطوتنا التالية هي إيجاد ANN مناسبة، مع أن تحقيق هذا الهدف قد يستغرق وقتًا كبيرًا.
شكر وتقدير
دُعم هذا العمل من المؤسسة الوطنية للعلوم الطبيعية في الصين (الأرقام 11973027 و 11933001 و 11601159)، ومن البرنامج الوطني الرئيس للبحث والتطوير في الصين (2019YFA0706601). كما نود أن نعرب عن شكرنا الصادق للمحكّم المجهول على تعليقاته القيمة.
إتاحة البيانات
البيانات التي تستند إليها هذه المقالة متاحة في المقالة وفي مادتها التكميلية على الإنترنت.
References
- Abraham et al. (2021) Abraham S. et al., 2021, MNRAS, 504, 3084
- Agarwal, Davé & Bassett (2018) Agarwal S., Davé R., Bassett B. A., 2018, MNRAS, 478, 3410
- Armstrong, Gamper & Damoulas (2021) Armstrong D. J., Gamper J., Damoulas T., 2021, MNRAS, 504, 5327
- Baqui et al. (2021) Baqui P. O. et al., 2021, A&A, 645, A87
- Bell, Bala (2015) Bell S., Bala K., 2015, ACM transactions on graphics (TOG), 34, 1
- Bhamare et al. (2021) Bhamare A. et al., 2021, in International Conference on Intelligent Technologies (CONIT), IEEE, p. 1
- Breen et al. (2020) Breen P. G. et al., 2020, MNRAS, 494, 2465
- Brownlee (2018) Brownlee J., 2018, Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python. Machine Learning Mastery
- Carruba et al. (2021) Carruba V. et al., 2021, MNRAS, 504, 692
- Clevert, Unterthiner & Hochreiter (2016) Clevert D. A., Unterthiner T., Hochreiter S., 2016, preprint (arXiv:1511.07289)
- Cranmer et al. (2021) Cranmera M. et al., 2021, PNAS, 118, 40
- Duchi, Hazan & Singer (2011) Duchi J., Hazan E., Singer Y., 2011, Journal of Machine Learning Research, 12, 257
- Gallardo (2006) Gallardo T., 2006, Icarus, 184, 29
- Géron (2017) Géron A., 2017, Hands-On Machine Learning with Scikit-Learn and TensorFlow. O’Reilly Media, Inc.
- Gladman et al. (2008) Gladman B., Marsden B. G., Vanlaerhoven C., 2008, in Barucci M. A., Boehnhardt H., Cruikshank D. P., Morbidelli A., eds, Nomenclature in the Outer Solar System, In The Solar System Beyond Neptune, University of Arizona Press, Tucson, p. 43
- Glorot, Bordes & Bengio (2011) Glorot X., Bordes A., Bengio Y., 2011, in Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, 15, 315
- Greydanus, Dzamba & Yosinski (2019) Greydanus S., Dzamba M., Yosinski J., 2019, preprint (arXiv:1906.01563v3)
- Hahn & Malhotra (2005) Hahn J. M., Malhotra R., 2005, AJ, 130, 2392
- Ivezić et al. (2019) Ivezić Ž. et al., 2019, ApJ, 873, 111
- Karpathy et al. (2014) Karpathy A. et al., 2014, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), p. 1725
- Khain et al. (2020) Khain T. et al., 2020, AJ, 159, 133
- Kingma & Ba (2015) Kingma D. P., Ba J., 2015, in Proceedings of the 3rd International Conference for Learning Representations, ICLR 2015 (arXiv:1412.6980)
- Lam & Kipping (2018) Lam C., Kipping D., 2018, MNRAS, 476, 5692
- Lawler et al. (2019) Lawler et al., 2019, AJ, 157, 253
- Levison & Duncan (1994) Levison H. F., Duncan M. J., 1994, Icarus, 108, 18
- Li et al. (2011) Li J., Zhou L.-Y., Sun Y.-S., 2011, A&A, 528, A86
- Li, Zhou & Sun (2014) Li J., Zhou L.-Y., Sun Y.-S., 2014, MNRAS, 437, 215
- Li et al. (2020) Li J. et al., 2020, MNRAS, 492, 3566
- Liu & Tegmark (2021) Liu Z., Tegmark M., 2021, Phys. Rev. Lett., 126, 180604
- Lucie-Smith, Peiris & Pontzen (2019) Lucie-Smith L., Peiris H. V., Pontzen A., 2019, MNRAS, 490, 331
- Maas, Hannun & Ng (2013) Maas A. L., Hannun A. Y., Ng A. Y., 2013, in Proceedings of the 30th International Conference on Machine Learning, 28, 3
- Malhotra (1993) Malhotra R., 1993, Nature, 365, 819
- Malhotra (1995) Malhotra R., 1995, AJ, 110, 420
- Malhotra (1996) Malhotra R., 1996, AJ, 111, 504
- McCulloch & Pitts (1943) McCulloch W. S., Pitts W. , 1943, The Bulletin of Mathematical Biophysics, 5, 115
- Mislis, Pyrzas & Alsubai (2018) Mislis D., Pyrzas S., Alsubai K. A., 2018, MNRAS, 481, 1624
- Nair & Hinton (2010) Nair V., Hinton G. E., 2010, in Proceedings of The 27th International Conference on Learning Representations, p. 807
- Nesvorný & Vokrouhlický (2016) Nesvorný D., Vokrouhlický D., 2016, ApJ, 825, 94
- Ng et al. (2015) Ng Y. H. et al., 2015, in Proceedings of the IEEE conference on computer vision and pattern recognition, p. 4694
- Petulante et al. (2021) Petulante A. et al., 2021, MNRAS, 504, 248
- Pike & Lawler (2017) Pike R. E., Lawler S. M., 2017, AJ, 154, 171
- Poincaré (1892) Poincaré H., 1892, Les methodes nouvelles de la mecanique celeste, Gauthier Villars, Paris, Vols. 1-3
- Qayyum et al. (2017) Qayyum A. et al., 2017, Neurocomputing, 266, 8
- Rosenblatt (1958) Rosenblatt F., 1958, Psychological Review, 65, 386
- Rumelhart, Hinton & Williams (1986) Rumelhart D. E., Hinton G. E., Williams R. J., 1986, Nature, 323, 533
- Sanil et al. (2020) Sanil N. et al., 2020, in International Conference on Artificial Intelligence and Signal Processing (AISP), IEEE, p. 1
- Schanche et al. (2019) Schanche N. et al., 2019, MNRAS, 483, 5534
- Sezer et al. (2020) Sezer O. B. et al., 2020, Applied Soft Computing, 93, 106181
- Sirimongkolkasem & Drikvandi (2019) Sirimongkolkasem T., Drikvandi R., 2019, Annals of Data Science, 6, 737
- Smullen & Volk (2020) Smullen R. A., Volk K., 2020, MNRAS, 497, 1391
- Stroescu et al. (2019) Stroescu A. et al., 2019, in 20th International Radar Symposium (IRS), IEEE, p. 1
- Sun et al. (2019) Sun H. et al., 2019, in Second Workshop on Machine Learning and the Physical Sciences (NeurIPS 2019), p. 1
- Tamayo et al. (2016) Tamayo D. et al., 2016, ApJL, 832, L22
- Tamayo et al. (2020) Tamayo D. et al., 2020, PNAS, 117, 31
- Ukwatta, Woźniak & Gehrels (2016) Ukwatta T. N., Woźniak P. R., Gehrels N., 2016, MNRAS, 458, 3821
- Valueva et al. (2020) Valueva M. V. et al., 2020, Mathematics and Computers in Simulation, 177, 232
- Vavilova et al. (2021) Vavilova I. B. et al., 2021, A&A, 648, A122
- Volk et al. (2016) Volk K. et al., 2016, AJ, 152, 23
- Yu et al. (2018) Yu T. Y. M., Murray-Clay R., Volk K., 2018, AJ, 156, 33
- Zhang et al. (2019) Zhang K. et al., 2019, ApJ, 883, 63